中文 · English
目录
- 0. 引子
- 1. 音频的特殊性 & Mel-spectrogram 作为”早期 latent”
- 2. 离散路线:Audio as Language
- 3. 连续路线:Audio as Latents
- 4. 升华:两条路在收敛,真正的争议在别处
- 5. 收尾:开放问题
0. 引子
2025 年 4 月,Sander Dieleman 在博客上发了一篇 ~60 分钟阅读量的长文 Generative modelling in latent space1。这篇文章是他多年做 latent 生成模型研究的一次系统梳理:从 JPEG / MP3 这种手工 latent 讲起,经过 VAE、VQGAN、latent diffusion 这一整条线,最终落到几个让人很难忘的论点上——感知信号的大部分其实是感知不到的噪声(所以两阶段范式才能成立);latent 是”高级像素”(而不是某种神秘的”语义”实体);rate-distortion-modelability 三个维度的 trade-off 决定了所有 latent 设计的形态。
这篇文章对视觉领域的研究者写得很完整,但对音频领域只在一处明确停下来说了一句:音频领域还没有形成广泛共识——既没有公认的”audio VQGAN”,也没有像 LDM 那样占据主导地位的工程模板。
这篇博客试图填这个空白。
我会用和 Sander 同样的笔触梳理音频生成的 latent 设计:音频领域目前有连续(latent diffusion / flow matching)和离散(codec + LM)两条路线,表面上它们是对立的设计哲学,但拆开看会发现它们实际上在向对方靠拢。真正决定音频生成未来的争议不是”discrete vs continuous”这个表面分歧,而是两个更深层的问题:
- 网格的暴政(每帧容量 vs 序列长度的 trade-off,音频比视觉更严重)
- Streaming vs offline(产品形态把这件事变成硬约束)
围绕这些问题,我会在文中抛出几个不太被讨论的判断(Hot Take),并把 Sander 的 rate-distortion-modelability 三角扩展成一个四面体——加上 streaming 这个被音频实时对话强行变成硬约束的第四维度。
文章按以下顺序展开:
- §1 铺垫:音频和视觉的物理差异,mel-spectrogram 作为前神经网络时代的 VQGAN。
- §2 离散路线:从 SoundStream 到 Moshi 的演化,RVQ 为什么成为音频 codec 的主流选择,AudioLM 范式正在如何被拆除。
- §3 连续路线:从波形扩散到 flow matching 的代际更替,连续 latent 的优势和代价。
- §4 升华:两条路在收敛,真正的争议在 §0 提到的两个深层问题上。
- §5 收尾:未解决的开放问题,以及多模态时代音频 latent 的位置。
读者最好是音频领域的研究者或工程师,对 Sander 那篇有基础印象会更顺。但我会尽量让没读过 Sander 的读者也能跟上——必要的概念会在出现的位置简述。
1. 音频的特殊性 & Mel-spectrogram 作为”早期 latent”
写到这里有必要往回退一步问个朴素问题:为什么音频生成会演化出离散和连续两条路?图像生成不也面对类似的设计选择,为什么音频里这两条路的分歧更剧烈、缝合更难?
答案有两层。一层是音频信号本身的物理特性——这决定了所有 latent 设计的基础约束。另一层是 mel-spectrogram 这个手工 latent 在过去十年里占据了音频生成的中心位置,它的影响一直延续到今天的 codec 设计直觉。这一节梳理这两件事,为后面”两条路在收敛”那个论点做铺垫。
1.1 音频和图像不一样的地方
音频和图像在生成模型设计上的差异,常被简化成”采样率不同”——但这只是表面。真正塑造表征设计的差异有四条:
1. 长上下文的一维信号。 音频是高采样率、长时间展开的一维序列:16 kHz 语音一秒 16000 个采样点,44.1 kHz 音乐一秒 44100 个。和 256×256 图像总共 65536 个像素相比,单秒 sample 总数其实差不多——关键差异不在数量,而在结构。图像的 2D 空间网格可以被压成短的 2D latent grid 并并行处理;而音频一旦扩展到几十秒或几分钟,时间步数线性增长,迅速变成长上下文建模问题。所以 audio latent 必须在时间维度上做激进下采样(从 16/44 kHz 压到 25/50/75 Hz 量级,比例 320× 起),否则下游 LM / diffusion 完全没法吃。
2. 相位的悖论。 人耳通常对绝对相位并不敏感——单个正弦波的起始相位变化、整段音频的极性翻转,都不会显著改变听感。但人耳对由相位错误引发的结构性失真非常敏感——周期性或不连续的相位偏差会破坏谐波之间的相干关系,产生机械感、金属感或 buzzing artifacts;瞬态区域的相位错误会改变波形的局部时间结构,使 onset 变钝、冲击感下降。所以音频生成中相位本身未必需要逐点精确匹配,但相位结构必须保持自然和一致。
这个不对称深刻影响 codec 设计。mel-spectrogram 直接丢掉相位(magnitude only),把恢复相位的工作甩给 vocoder。Neural codec 的训练目标也隐式承认这件事——EnCodec / DAC 的 multi-scale STFT discriminator 虽然吃的是 complex STFT(含 phase),但 adversarial 训练只要求”看起来像真的”而不要求 sample-level 严格对齐;mel L1 又完全 magnitude-only;所以整体优化压力对”波形 phase 逐点对齐参考”的约束很弱,默认”sample 对齐是 decoder 的私事”,靠 decoder 学到的归纳偏置补出来。
3. 感知的各向异性。 视觉里 LPIPS 这类 learned perceptual similarity metric 提供了一个相对稳定、可微的感知距离近似——和 reconstruction / adversarial / diffusion objective 结合时,常常能提升生成的感知质量。音频里缺少同等公认、通用、训练稳定的对应物。心理声学传统工具(mel filterbank、Bark filterbank、auditory masking)本身是可微的,mel L1 就是 codec 训练里天天用的 loss——但它们是手工构造的局部听觉近似,难以完整覆盖音色自然度、瞬态清晰度、相位结构一致性这些更复杂的感知维度。评价侧的 PESQ / STOI 通常不适合作训练 loss;UTMOS 这类 learned MOS predictor 可以做 loss 或 reward,但直接优化容易引入 metric bias,未必能泛化到所有 codec 设计。结果就是 codec 训练只能堆 multi-scale STFT、mel loss、waveform loss、multi-period discriminator 这一组间接目标,从不同局部视角逼近真实听感——而不能像视觉一样直接用一个 LPIPS-style loss 约束生成。
4. 纹理与结构:音频版的 stuff vs things。 Sander 原文里有一个很好的 framing:图像内容分 texture(stuff)和 structure(things)两类。草地的纹理是高熵的,但人眼无法区分同一纹理的不同实现——我们感知到的是”草”这个不可数的类别,不是每一根草叶。原图和重建图并排看一模一样,叠在一起来回切换才会暴露纹理区域其实差很远。而狗的眼睛这种 structure,同样幅度的差异立刻被看到。所以好的 latent 应该抽象掉 texture、保留 structure——只记”这里有草”,不记每根草叶的位置。这让 autoencoder 可以丢掉海量纹理模态,也让 latent 上的生成模型只需要建模纹理的”有无”,而不用背下纹理的全部熵。
音频里有完全对应的现象,而且心理声学早就给了它名字——sound texture。McDermott & Simoncelli2 的经典工作证明:雨声、掌声、火焰噼啪、虫鸣这类声音,人耳是通过时间平均统计量感知的,不是通过具体波形实现——两段不同实现、相同统计量的雨声,听起来就是同一场雨。语音里的对应物更日常:清辅音 /s/ /f/ 的本质是被频谱包络整形的噪声,同一个包络下换一个噪声实现,听感完全一致;混响尾巴也是统计感知的——我们听到”房间很大”,不是每一次反射。这些是音频的 stuff。音频的 things 则是:基频轨迹(错一点立刻听出来)、共振峰(决定音素身份)、瞬态(钢琴的 attack、爆破音的 burst,时间上糊一点就毁)。同样幅度的偏差,落在 texture 上人耳听不见,落在 structure 上是刺耳的 artifact。注意这和第 2 条相位悖论是同一件事的两面:噪声成分的相位是纯 texture(完全可交换),谐波之间的相位关系是 structure(必须保持相干)。
但音频和视觉之间有一个重要差异,也是 audio latent 更难做的原因之一:视觉的 texture 和 structure 在空间上是分区的,音频的在时频上是叠加的。一张图里草地占一块区域、狗眼占另一块,latent 可以按空间位置分配容量;而音频里 /s/ 紧跟在元音后面几十毫秒内、混响尾巴叠在下一个音节上、镲片的噪声 wash 和贝斯线同时存在于同一帧。想”抽象纹理、保留结构”,视觉靠空间分配就行,音频必须靠某种成分分解——谐波 vs 噪声、周期 vs 非周期。
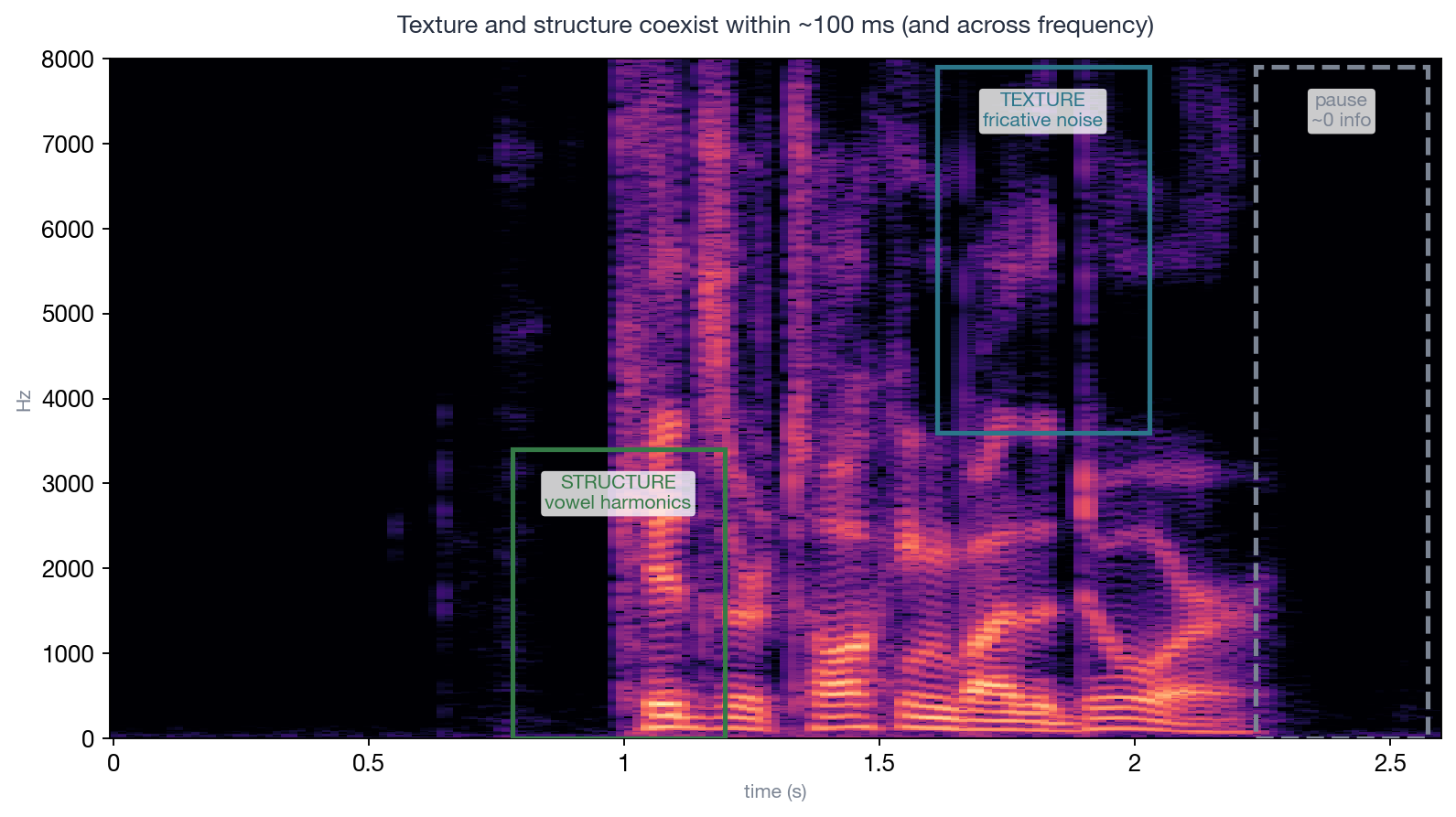
caption:”同一句话里,texture 和 structure 相隔不到一百毫秒:绿框里是元音的谐波横纹(structure——基频轨迹错一点立刻听出来),蓝框里是 /s/ 的噪声块(texture——换一个噪声实现听感完全一致),虚线框里是停顿(几乎零信息)。视觉里草地和狗眼各占一块区域,音频里这三种东西在同一条时间轴上交替出现、在同一帧的不同频段共存——这就是’时频叠加’的含义,也是恒定帧率 codec 浪费容量的直接原因。”
有意思的是,经典音频编码三十年前就在做这件事。LPC 把激励信号分成”周期脉冲串 vs 噪声”两类;STRAIGHT / WORLD 这类 vocoder 有专门的 aperiodicity 参数;AAC 的 PNS(Perceptual Noise Substitution, 1997)干脆把噪声型频带编码成一个标志位加能量值——解码时用随机噪声重新生成。”只编码纹理的存在和统计量、不编码纹理的实现”——Sander 描述的这条 latent 设计原则,音频编码工程师在 90 年代就当作省 bit 的窍门用上了。Neural codec 这一代其实继承了这个直觉,只是把显式的成分分解换成了隐式的对抗训练:GAN-based decoder 生成的噪声实现和原始信号 sample 级对不上、统计上等价——这正是 §2.1 会讲到的”DAC 负 SI-SNR”现象的感知学根源,也是 Sander 那个”叠图实验”的音频版。
这四条差异共同导致一件事:音频不能直接套用视觉的 latent 框架,必须有自己的设计哲学。 §2 离散路线和 §3 连续路线的所有分歧,都是在回应这四条约束。其中 texture/structure 这条会反复回来:mel + vocoder 范式的成功(§1.2)本质上就是一次 texture abstraction,而 texture 段只需要统计量、structure 段需要密集 bit 这个事实,是第 4 节”网格暴政”的信息论根源。
1.2 Mel-spectrogram:你早就在用的那个 latent
音频生成里最有影响力的”latent”不是学出来的。它是 1980 年代信号处理学家设计的,一行 SciPy 代码就能算出来:
mel = librosa.feature.melspectrogram(y=waveform, sr=22050, n_mels=80)
得到一个 [T, 80] 的矩阵。然后你就把它当 latent 用了——前面用 Tacotron 或 FastSpeech 从文本生成它,后面用 HiFi-GAN3 从它合成波形。这套范式跑了五年、产出了几十篇高引论文,到 2022 年还是 TTS 论文的默认前端。
我们没有把它叫做 “audio VAE” 或 “audio learned latent”。它就叫 “mel-spectrogram”——一个 1980 年代的工程概念。但如果你把 Sander 在原文里讲的两阶段 latent framing 拿来套这件事,会发现一个让人略微不舒服的真相:mel 完美符合”learned latent”应有的所有性质,只是它不是学的,是手工攒的。
让我们一条一条对照。
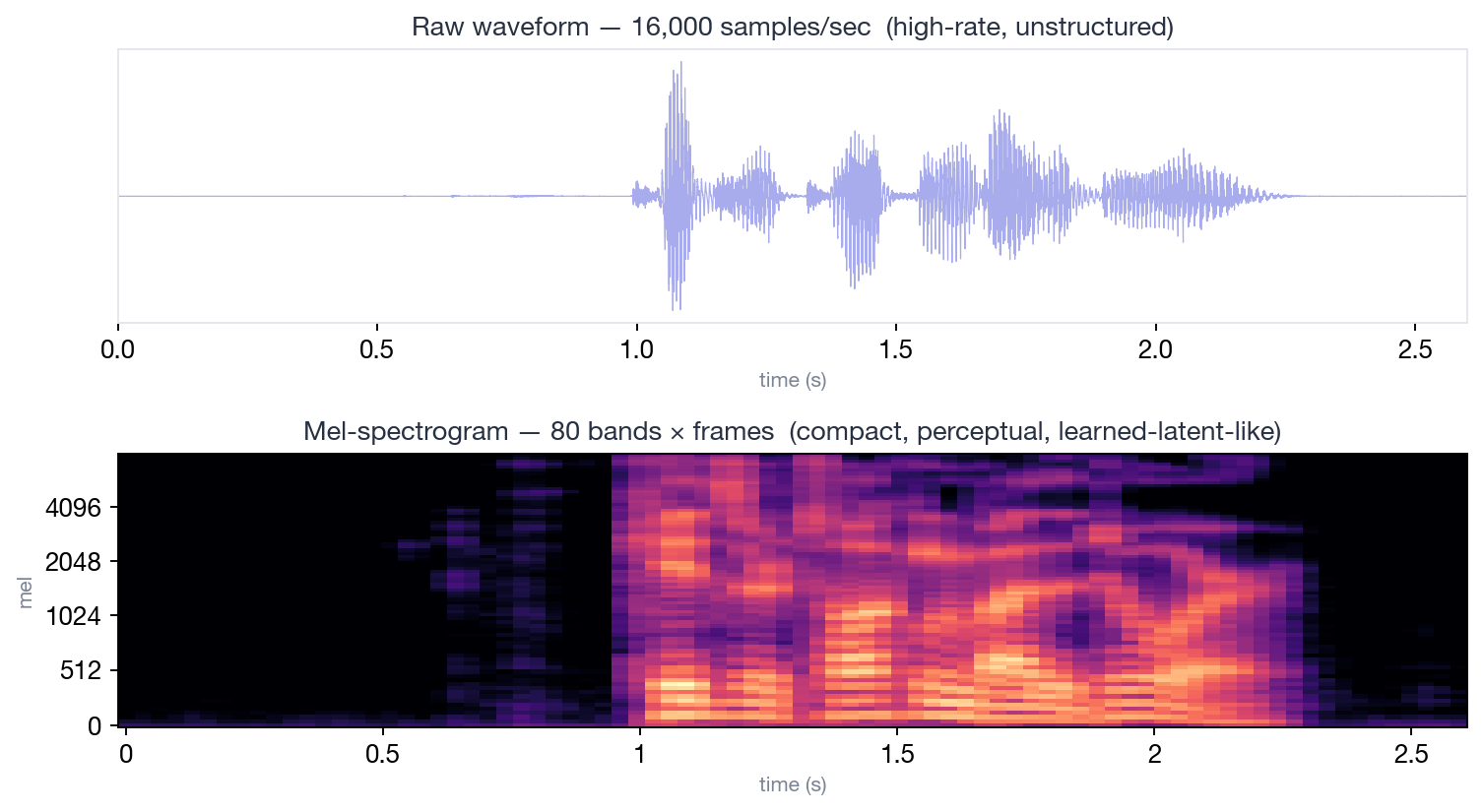
caption:”这就是 2017-2022 五年里 TTS 真正在建模的’latent’——它甚至不是学的,是 SciPy 一行算出来的。但它丢掉相位、压缩了高频、模仿了人耳——所有 learned latent 该做的事它都做了。”
有损? Mel 直接丢掉了相位。一个 80 维 magnitude vector 无法唯一还原 STFT,更不能唯一还原波形——所以从 mel 还原音频本质是一个 ill-posed 问题,需要 vocoder(无论是 Griffin-Lim 还是 HiFi-GAN)来”猜”出 plausible 相位。用 §1.1 第 4 条的语言说:mel 丢掉的恰好是音频里最大的 texture 熵源(噪声成分的相位实现),保留的恰好是 structure(谐波位置、共振峰、能量轮廓)——mel 是一次手工设计的 texture abstraction,vocoder 的工作就是幻觉出一个感知等价的纹理实现。这种”丢掉某些维度、靠 decoder 补回来”的设计,和 VQGAN 把 256×256 图像压成 16×16 latent 在精神上一样——都假设丢掉的部分不重要、decoder 可以从上下文 fill in。
有结构? Mel 不是一个 flat vector,是一个时-频 2D 网格。每个时间步对应一帧(大约 12.5 ms),每个频率 bin 对应一个 mel scale 上的频带。VQGAN 的 latent 也是 2D 网格(空间),mel 是 2D 网格(时间 × 频率)。两者都不指望把”内容”压缩成一个固定向量,而是保留一个低分辨率的结构化表示——一个让下游容易吃的”信号缩略图”。
有感知动机? Mel scale 不是工程师拍脑袋的,它的出身甚至和音频处理无关——1937 年 Stevens、Volkmann、Newman 三位实验心理学家做了一组纯主观实验:让听者调音高,使一个音听起来”恰好是另一个音的一半高”,由此测出主观音高和物理频率的非线性映射,”mel” 这个词就取自 melody4。把它做成语音特征要等到 1980 年 Davis & Mermelstein 的 MFCC5。换句话说,mel 是 1930 年代研究”人耳怎么听”的副产品,而不是任何人为建模音频而设计的东西。但正因为它忠实地压进了听觉感知结构——对数频率轴对应耳蜗基底膜的响应(低频精细高频粗略)、临界频带对应掩蔽效应——用 mel 当 latent,就等于免费拿到了一份人耳的 “perceptual prior”。这正是 VQGAN 用 LPIPS-style perceptual loss 想学的东西,只不过 mel 是用心理声学常识、提前几十年手工凑齐的。
可建模性好? 这点最实用。Mel 帧之间有强时间相关性,对 RNN / transformer 都友好;维度 80,比 22050 Hz 波形低两个数量级。这是为什么 2017 年 Tacotron 选择 text-to-mel + vocoder 两阶段——直接端到端学 text-to-waveform 当时建模太难,而 text-to-mel 把建模难度降了一个数量级。
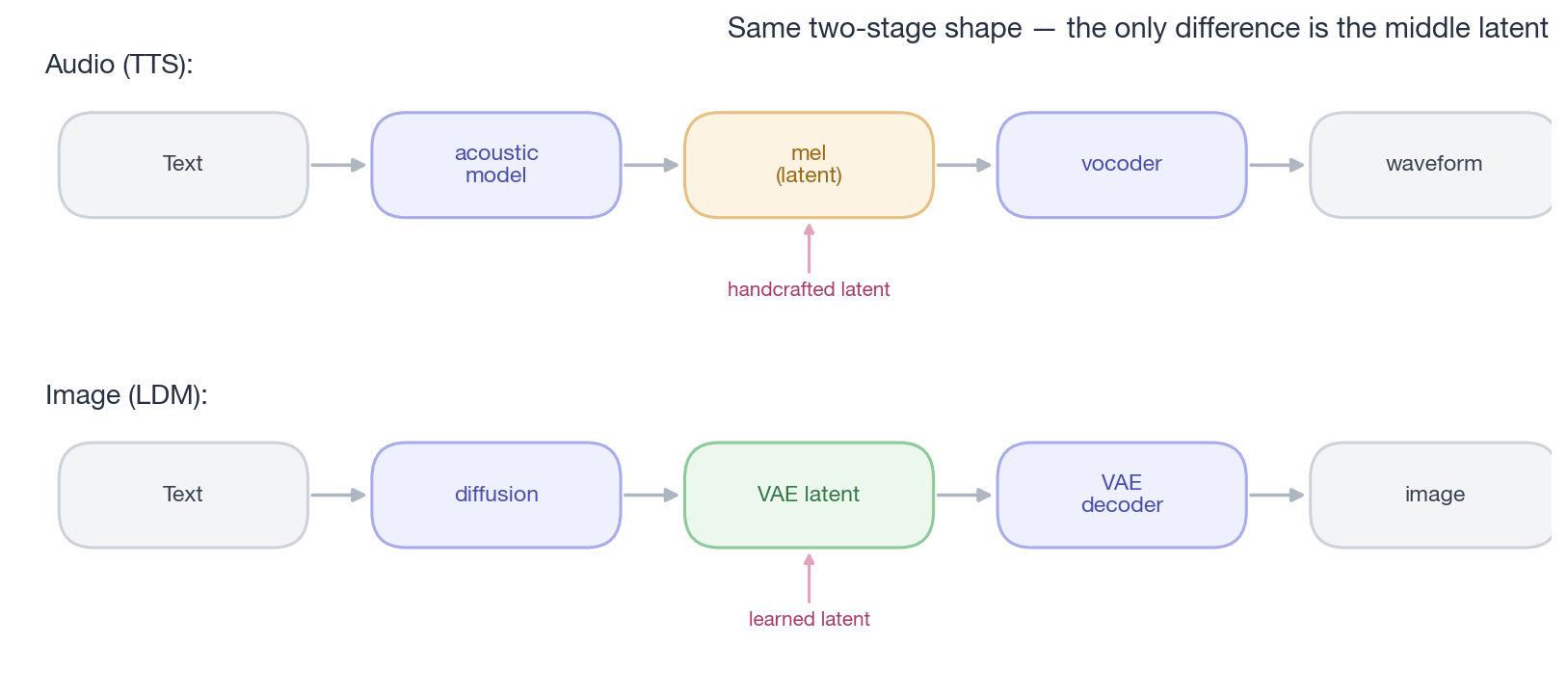
caption:”两个领域的两阶段范式在结构上完全一致。唯一区别是音频的中间那层 latent 是手工的,图像的是学的。所以问题不是’音频要不要走 LDM 那条路’,而是’什么时候把手工 latent 换成学出来的’。”
这套范式真的跑得很好。 Tacotron 1/26、FastSpeech 1/2、Glow-TTS、VITS——整个 2017-2022 年的 TTS 黄金时代都在这个框架里。在单说话人 + 足够数据 + 受控场景下,输出已经能让人短时间分辨不出是合成。如果你把这五年所有 TTS 论文堆在一起,会发现一个有意思的现象:所有人都在改进第一阶段(text-to-mel),但没人质疑第二阶段为什么是 mel。 Mel 几乎成了大家默认接受的”physics of audio”——像图像里的 RGB 一样自然,不需要为它辩护。
这里值得停一下:当一个 latent 表示在一个领域统治五年没人质疑,它通常不是因为这个 latent 最优,而是因为它先到了、并且足够好。 Mel 就是这种情况。
那它为什么后来被 neural codec 取代了?因为有人开始问:”如果我让这个 latent 也是学的,会怎样?”
这件事在视觉领域 1990s 就经历过一次。
JPEG 和 MP3 也是手工 latent——DCT 把信号变成频域系数、心理感知模型决定哪些系数能扔、Huffman 编码压缩剩下的。这套设计在 1990s-2010s 工程上极其成熟,到今天你打开手机相册里看到的图背后大概率还是 JPEG 或它的后代。但 JPEG 有个根本天花板:它的”表征空间”是工程师在 1985 年根据当时心理感知研究决定的——一旦 DCT 基函数定下来,所有 JPEG 编码出来的图都活在这个固定的子空间里。
VQGAN(Esser et al., 2021)7做的事情很简单:让 latent 自己学。Encoder 把图片压到 16×16 网格,decoder 学着重建。学出来的 latent 不再被”工程师当年想象中信号该长什么样”约束,它会捕捉数据里真正重要的统计结构。结果是生成质量上把 JPEG 那一代甩开了一个数量级——不是因为算法多神奇,而是因为 prior 不再被锁死。

caption:”音频的中间那层 latent,终于从手工的(mel + vocoder)换成了学出来的(neural codec)。而这个学出来的’codec’,本质就是 VQGAN 那套学出来的 VQ——只是 codec 这个名字,掩盖了这层同源。”
Audio codec 这一代——SoundStream / EnCodec / DAC——做的事情,从 latent framing 看,就是 JPEG → VQGAN 在音频上的对应历史。 把工程师手工设计的 latent 换成数据学出来的 latent。这条类比当然不完全精确(audio codec 强烈继承了压缩-传输的工程基因,VQGAN 一开始就是为了下游生成而设计的),但作为 framing 是清晰的。
有几个细节让音频版这次转变读起来不太一样:
它迟到了。VQGAN 是 2021,SoundStream 同年——但音频 learned codec 真正成为下游生成模型的默认前端,要到 EnCodec 2022 + VALL-E/MusicGen 2023 才发生。两年之差不大,但社区接受”手工 latent 该退场了”这件事的速度,音频比视觉慢了一拍。
它保留了 “codec” 这个名字。它没有被叫做 “audio VQGAN”。这个命名延续部分掩盖了它和图像 VQGAN 的同源性——大家把它当成”压缩工程的下一代”,而不是”生成模型的下一代”。这个 framing 偏差影响了整整一代 codec 的设计选择(§2.1 会展开)。
它的工程模板更趋同。SoundStream / EnCodec / DAC 的架构高度相似——卷积 encoder + RVQ + multi-discriminator——比图像 codec 那一代的多样性更窄。这是音频感知约束更严的代价。
但故事还有一个反转:mel 其实没真的退场。 learned latent 接管了”压缩-还原”那一层,可如果你翻看最近这批 audio tokenizer 和生成系统,会发现 mel 一次次地以另一种身份回来——不是作为最终表征,而是作为被 tokenize 的对象、或被预测/重建的目标。dMel 直接把 mel 的频带量化成 token;一大批 flow-matching / diffusion 系统(Grad-TTS、Matcha-TTS、E2-TTS、MELLE,乃至刚提到的 TML-Interaction)干脆就在 mel 上做生成;很多 codec 的训练目标里也压着一项 mel 重建 loss。
为什么 mel 像打不死的小强一样反复回来?因为它身上那几条性质,恰恰是一个”好被建模的中间表示”梦寐以求的:结构信息干净——时频网格上音素、谐波、能量包络一目了然,语义结构浅层可及;作为输入友好——规整的 2D 结构、维度低、分布稳定,喂给任何网络都不挑食;作为预测目标容易——相邻帧高度相关、上下文连续,模型预测下一帧的不确定性天然小。这三条放在一起,正是 §2.5 那个”可建模性”工具箱的雏形——只不过 mel 是用手工方式、提前几十年就把它凑齐了。所以与其说 learned latent 取代了 mel,不如说它们一直在重新发现 mel 早就具备的好处,并试图用学习的方式把这些好处做得更极致。
把这条线索接到后面就顺了:§2 的离散路线 = mel + vocoder 范式被换成”learned discrete latent + audio LM”;§3 的连续路线 = mel + vocoder 范式被换成”learned continuous latent + diffusion/flow matching”。两条路解决的其实是同一件事——把手工 latent 换成学出来的 latent。 它们的分歧只在第二阶段的建模工具(LM vs diffusion/flow)和第一阶段的 latent 类型(discrete vs continuous)上。这两条分歧在第 4 节会被论证其实在向中间收敛。
但站在这一节先看清第一代 latent 是什么、好在哪、被取代的逻辑是什么——后面所有讨论的地基才打得稳。
2. 离散路线:Audio as Language
如果说连续路线是把 Sander 那套 “latent 是高级像素” 的叙事原封不动搬到音频,那么离散路线的野心更大一些——它试图把音频整个变成另一种文本。Token、词表、自回归、上下文学习,这些为语言模型量身定做的概念在被音频接管之后,并非简单的工程类比。它们带来的可能性是:让”听懂一段声音”和”说出一段声音”共用一套底层表征,从而绕过视觉领域里”理解走 CLIP、生成走 latent diffusion”那种各走各路的格局。
这是一个野心很大的赌注。这一节会沿着 SoundStream → EnCodec → DAC 这条工程主线推进;中间花较多笔墨讨论 RVQ 为什么成了大多数音频 codec 的默认选择,以及 AudioLM 范式为什么要发明 “semantic token + acoustic token” 这种音频独有的奇怪分工——以及为什么这种”两套 tokenizer”的工程形态正在被单一 codec 收编。最后落到下游 LM 的几种典型建模姿态(VALL-E、MusicGen、Moshi),并以一个 Hot Take 收尾。但这个 Hot Take 比我一开始想写的更克制——离散路线的赌注成不成立,今天还在天平上摇摆。
2.1 从 VQ-VAE 到 SoundStream / EnCodec / DAC
离散音频 codec 这件事,早在 2017 年就该发生,却迟到了四年。
VQ-VAE 的原始论文里就有语音——van den Oord 等人 20178 在 VCTK 上演示过,学到的离散 code 能留住说话内容、丢掉说话人身份。这几乎就是后来 “semantic vs acoustic” 整条思考线的胚胎。技术摆在那里了。但接下来四年,没有人把它推成一个能用的东西。
为什么?三个拦路的东西,每一个都很实在。波形太长——16 kHz 一秒一万六千个采样点,直接在波形上量化,要把码率压到自回归模型扛得动的范围非常难;Jukebox(OpenAI,2020)9用三层多分辨率 VQ-VAE 在音乐上硬闯了一次,证明了”音频确实能变成 token 再用 LM 建模”,但采样慢到没法用、artifact 肉眼可辨。mel + vocoder 已经够好——2018 到 2021 那几年,TTS 社区的注意力全在 Tacotron / FastSpeech + HiFi-GAN 这套两阶段范式上,手工 latent 用得正顺手(§1.2 讲过为什么),没有迫切的理由去换。下游的工程栈还没长好——2020 年的 transformer 处理长序列远没今天高效,而音频 token 一秒就是几百个,谁也不想喂给当时的模型。
转折点是 SoundStream(Zeghidour et al., Google,2021)10。它最重要的贡献不是某个单一技巧,而是把”codec”这个工程框架干净地搬进了 neural audio——它不是最早的神经音频压缩(Kleijn 2018 已经试过),但它第一个把这条线做成了一个清晰、可复用的模板:卷积 encoder/decoder 端到端,目标函数里同时塞进重建、对抗(multi-scale STFT discriminator)和码率约束。模板一旦立住,后面整代工作都照着它长。模板里还埋了两个会反复出现的零件:RVQ(残差量化,份量太重,留到 2.2 单独讲)和 quantizer dropout(一个模型支持多档码率,scalable bitrate 的源头)。
EnCodec(Défossez et al., Meta,2022)11把这个模板打磨成工业级——加 LSTM、扩到 24 kHz 全频带和 48 kHz 立体声、开源代码和权重。开源这步看着平平无奇,却是决定性的:紧接着的 VALL-E、MusicGen 直接拿 EnCodec 当前端。一个 codec 只要免费、好用,就会在一两年内变成一整代下游工作的默认依赖——视觉领域看 VQGAN 普及的时候,我们已经见过这部剧本一次了。
然后是 DAC(Kumar et al., Descript,2023)12,当前重建质量最强的通用 codec 之一:snake activation 引入周期性偏置、多尺度 + 多周期 discriminator、factorized + L2-normalized 的码本,把 6 kbps 这种低码率下的客观重建质量又往上顶了一截。
但 DAC 身上藏着一个细节,值得在这里停一下——因为它后面会反复回来。DAC 的优化目标偏向感知质量,而不是波形保真。 在音乐和通用音频上,它重建出来的 SI-SNR 甚至是负的:从 sample 维度看,重建信号和参考的差异比纯噪声还大;可 VISQOL、UTMOS 这些感知指标照样很高。这不是 bug,是设计哲学——一个用 perceptual GAN 训出来的 codec,它做的本质是 perceptually equivalent re-synthesis:人耳听着一模一样,但 sample 是重新合成的,相位被改写、瞬态被微调,时域根本不严格对齐。
为什么 DAC 滑到这一端、EnCodec 却没有?根子在 loss 配比。codec 训练那一堆损失里,真正强制”波形 sample 对齐参考”的其实只有 time-domain L1 一项——mel L1 只看 magnitude、丢相位,multi-scale STFT discriminator 只要”看起来真”不要求逐点对齐(判别器看得到相位 ≠ 强制相位对齐),都是 phase-tolerant 的。EnCodec 专门用一个 Loss Balancer 把 time-L1 的梯度按住、不让对抗项盖过它;DAC 没有这道闸,还额外加了 phase-invariant 的 multi-period discriminator 和 Snake 激活的周期性偏置——于是优化自然滑向”满足所有 phase-tolerant 项、放弃 sample 对齐”的解,也就是 re-synthesis。
这件事真正的意义不在 DAC,而在怎么读 codec 的 benchmark:拿 sample-level 指标(SI-SNR、SDR)去评一个 perceptual loss 训出来的 codec,量到的是 metric 和它设计哲学的错配,不是它的能力——比如 source separation 的 SI-SDR 对 DAC 会难看一截,但换成 perceptual MOS 或 ASR-on-separated,结论很可能翻过来。记住这个 metric 偏置,它在第 3、4 节比较连续与离散时还会回来——很多”离散输给连续”的结论都带着同一种偏差。反过来,DAC 这种偏好让它的 token 更保留音色、共振峰、能量包络,所以在 speaker recognition 这类依赖音色的下游任务上反而比 EnCodec 强(DASB benchmark13 上看得很清楚)。
把 SoundStream、EnCodec、DAC 摆在一起,有一件略微让人不安的事:它们长得太像了。卷积 encoder 把波形按 2× 一级级下采样到 50 或 75 Hz,接一个 RVQ bottleneck,再对称地卷上去;loss 永远是重建 + 对抗 + commitment 那一套。这种趋同不全是好事——它说明的不是”问题解决了”,而是整个设计被一个很窄的目标(多频带重建质量 + 固定码率)牵着走,一旦认下这个目标,剩下能动的空间就所剩无几。
这背后是 “codec” 这个词自带的基因。它来自 audio coding——MP3、AAC、Opus 那一脉,骨子里关心的是压缩与还原的对偶。这跟图像 VQGAN 的出身正好相反:VQGAN 从一开始就是为”让 latent 能被 LM 建模”而生,重建只是手段。音频 codec 一上来就更工程、更盯 perceptual quality,把”下游好不好建模”当成了副产品。
这种对感知质量的偏执还有一层更深的根:音频的瑕疵比图像的更难被原谅。图像里一块纹理偏一点、颜色挪几个色阶,眼睛扫过去就放过了——视觉对局部静态误差的容忍度很高。但音频是流动的,人耳对某几类失真极其敏感:一个 click、一帧 buzzing、一处谐波错位,会瞬间从连续的听觉流里跳出来,而且一旦被听见就再也忽略不掉,整段的质感都塌了。这就是为什么音频圈把 MUSHRA / MOS 主观听测奉为金标准,也是为什么 codec 设计者宁可堆四五个 discriminator 也要把感知质量焊死——在音频里,”重建差一点”常常不是质量轻微下滑,而是 artifact 直接暴露。
这个出身塑造了它的偏好,也圈定了它的盲区——比如对变长 tokenizer 几乎零探索,这点留到第 4 节再算账。
2.2 RVQ 的流行:为什么音频 codec 大多选择残差量化
RVQ 是音频 codec 这一代最具有”音频特色”的设计选择。它的存在感这么强,以至于你打开任何一篇 2022 年之后的离散音频论文,第一张图里几乎都有那个层级残差的方框。Mousavi et al. 的 survey14 列了 55 个左右的离散音频 tokenizer,其中超过半数都用 RVQ 或其变体;剩下的也基本是在挑战 RVQ 的某个具体痛点,而不是另起一套体系。
为什么需要它?
考虑一个 24kHz 的音频,卷积下采样 320 倍到 75 Hz 帧率。一帧用单层 VQ,code book 大小 1024,每帧 10 bits,码率是 750 bits/sec ≈ 0.75 kbps。这个码率对语音感知质量来说远远不够——人类语音可懂的下限大约在 2–3 kbps,高保真还原一般需要 6 kbps 以上。
直觉的解决方案是扩大 codebook:把 1024 提到 16384 甚至 65536。但单层 VQ 在 codebook 较大时(尤其超过几千量级)更容易遇到 codebook collapse / 利用率下降——大量码字根本不会被选中,有效容量远低于名义容量。具体阈值取决于训练数据规模、encoder 容量、commitment loss 和 codebook update 策略。RVQ 的解法是把容量拆成层。第一层 codebook 量化原始 latent,第二层量化第一层的残差,依此类推。N 层下来,最终重建是 q₁ + q₂ + … + q_N。每一层 codebook 只面对自己那层残差的分布——量级越来越小、结构越来越细——所以每个 codebook 都不需要太大,1024 大小也够用。8 层 × 10 bits = 80 bits/frame × 75 Hz = 6 kbps,正好到达高保真区间。
RVQ 的副产品:层级语义
RVQ 真正有意思的地方不是容量本身,而是层级带来的意外副作用:第一层 codebook 自然承担 coarse 信息——基频、音素轮廓、整体能量;后续层逐渐编码音色细节、相位、瞬态、噪声。这个层级不是设计目标,它是优化压力下自然涌现的——第一层要在最少 bit 内最大化重建,必然抓最具区分度的信号。
这个副作用决定了后面所有下游建模的姿态。AudioLM15 之所以可以”semantic LM 只看 SoundStream 前几层”,Mimi 之所以可以”通过 WavLM16 distillation 把语义信号塞进第一层”,都是吃这个 free lunch。这一点 2.3 会展开。
代价
序列长度从 T 变成 T × N。一个 30 秒、75 Hz、8 层 RVQ 的音频是 30 × 75 × 8 = 18000 个 token。这逼迫下游 LM 必须采用”非平凡”的展开方式——VALL-E 把第一层和后续分开(AR + NAR),MusicGen 用 delay pattern 让多层并行预测,UniAudio/Moshi 用 local transformer 在 codebook 维度做小型 AR。2.4 节专门讨论这些姿态。
量化方法的小景观
虽然 RVQ 占主导,但量化算法的实际景观比”RVQ vs lookup-free”二分要丰富得多。挑几类有代表性的(更全的八类分法见前面那篇 survey):
- SVQ(Single VQ)——单一大码本(WavTokenizer17、BigCodec18、TS3-Codec19、dMel20)。押注的是单码本让下游 LM 的展开足够简单:每帧一个 token,没有 delay pattern 或 local transformer 的负担。代价是单码本一帧能带的信息有限(log₂4096 ≈ 12 bits),于是得配更大的 encoder/decoder、并把帧率顶高才能保质量(WavTokenizer 75 Hz、BigCodec 80 Hz)。压到 40 Hz 重建就明显退化——”低帧率 + 单码本”有个底线,要做到 Mimi 的 12.5 Hz 似乎非多码本不可。
- RVQ——层级残差,前述主流。
- MSRVQ(Multi-Scale RVQ)——SNAC21 的做法:不同 RVQ 层跑在不同时间分辨率上(粗结构低帧率、细节高帧率,实际是 12 / 23 / 47 Hz),算是在 RVQ 框架内做出变长的一种妥协。我们的 LLM-Codec22 再加一层巧思:码本直接取自 LLM 的词向量(§2.3),于是这些多尺度 token 同时”对齐到文本词表”——在 LLM 眼里既分了粗细、又像文字。
- FSQ(Finite Scalar Quantization)23——把每个维度独立量化到固定离散等级,不需要 nearest-neighbor lookup,也不会 collapse。在视觉里 MAGVIT-2 等用得很成功。音频上 SQ-Codec、Spectral Codecs、HARP-Net 等使用——值得注意的是这篇 survey 的 controlled ablation 里发现 FSQ 在 16 kHz 上 UTMOS/DNSMOS 居然超过 RVQ,感知层面 FSQ 不见得输。
- 其余几类只是在改进 RVQ 的某个具体环节、而非另起体系:GRVQ(HiFi-Codec24 把 latent 切成多组各自做 RVQ,缓解第一层过载)、CSRVQ(ESC25 在 encoder/decoder 多个层级逐步 refine)、PQ(子向量分别量化,Best-RQ26 等 SSL 常用),以及”用 k-means 把 SSL(HuBERT27 等)隐层特征后置离散化”这种 SSL-as-encoder + 量化的路子(本质不是 codec,§2.3 细讲)。
回头补一句前面 SVQ 那条留下的伏笔。我们说”单码本要保质量就得高帧率”,但这个底线有个前提:它是在”直接重建波形”的设定下成立的。一旦把目标换成 mel——直接 tokenize mel、或让 decoder 重建 mel——难度立刻降一档:mel 熵低、没相位、上下文连续(§1.2 那几条好性质),单层 VQ 压到 25 Hz 不少工作都做得到,把还原波形的脏活留给一个独立 vocoder。这又是 mel 没真的退场的一个佐证——它把”单码本能压多低”这条线往下挪了一截。
为什么音频还是以 RVQ 为主?这个问题得先分清楚问的是哪一层。
如果问的是 codec 本身——端到端”波形压成 token、再从 token 还原回波形”这件事——RVQ 确实仍是主流,三层原因。
第一,也是最实在的一条:RVQ 能同时拿到高保真和低帧率。这两件事对单层 VQ 是矛盾的——前面那条讲过,单码本要保质量就得把帧率顶上去(WavTokenizer 75 Hz、BigCodec 80 Hz)。RVQ 用层级残差把容量摞起来,于是可以在很低的帧率(Mimi 12.5 Hz)下还原出高保真音频。而帧率直接决定下游 LM 的序列长度,低帧率 = 短序列 = 好建模,这是 codec 给下游最值钱的一份礼物。单层很难两头都要。
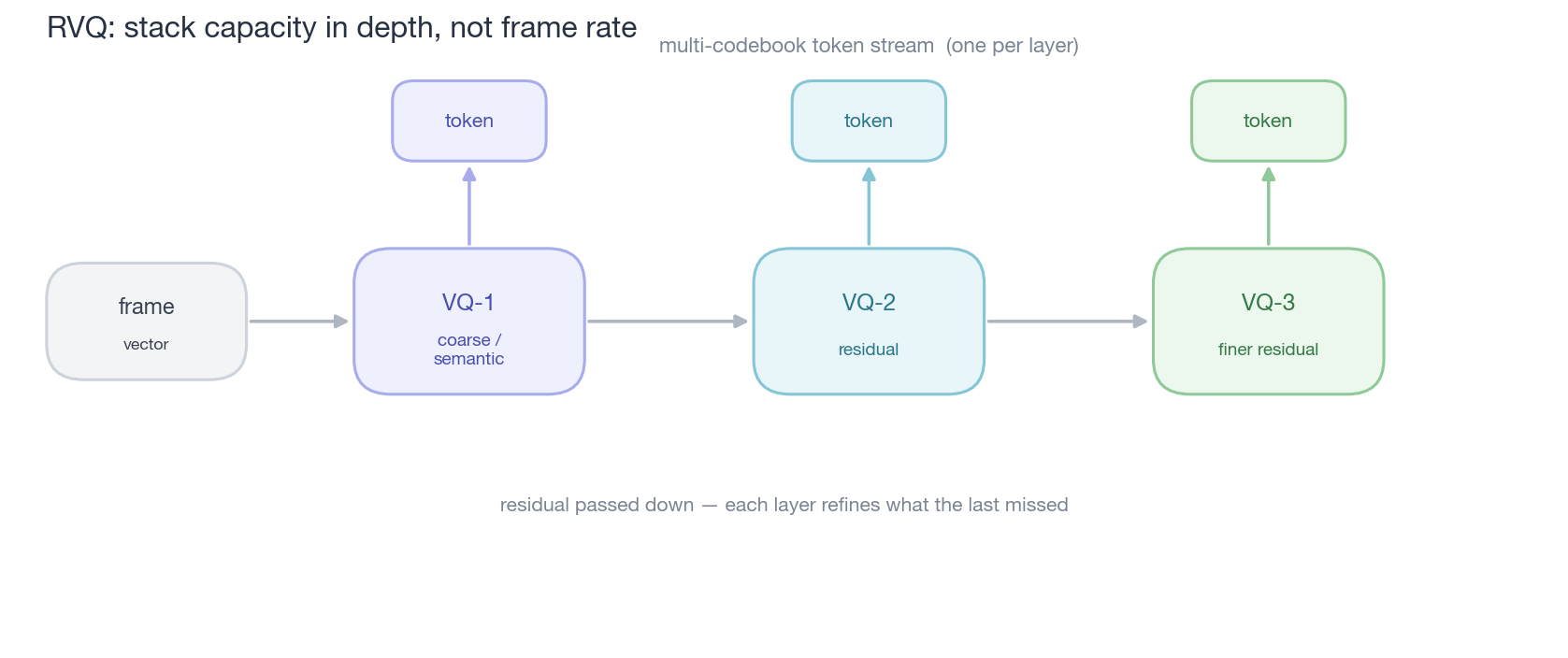
caption:”RVQ 的算盘——不靠堆帧率,而靠堆层级深度来攒容量。第一层量化最粗、承载语义和最大能量,后面每层量化前一层的残差、补越来越细的细节;每层吐一个 token,合起来是一条 multi-codebook 流。于是同一帧能塞下高保真所需的信息,帧率却压得很低——这正是它最值钱的地方。”
第二,生态惯性。EnCodec/DAC 是免费、好用的预训练 codec,围绕多层 RVQ 又攒出了一整套下游配方(delay pattern、local transformer、训练 trick),新工作顺手拿来就用。顺带澄清一个常见误解:换到单层 SVQ,下游不是”要重新设计”,恰恰相反——是直接简化掉(每帧一个 token、标准因果 LM 直接喂,delay pattern 全省)。所以 SVQ 的代价不在下游,而在 codec 端那个”保真 × 低帧率”的两难——这正好回到第一条。
第三,更本质的原因:RVQ 的层级是结构性免费给的,其它方案没有。FSQ/LFQ 的维度在语义上是等价的,SVQ 又是单一码本根本没有层级——想做 semantic / acoustic 解耦,只能靠额外训练目标硬掰。一旦失去这个免费层级,AudioLM 系”第一层管语义、后面层管声学”的整套设计哲学就得重做。视觉领域承受得起这种重做(那边 semantic / acoustic 解耦不是核心需求),音频承受不起——这一点是 §4.2 那个判断的核心论据。
但如果问的是”当下主流的音频生成系统还在用 RVQ 吗”,答案就微妙得多。 最近一年的一批生产级 TTS 系统——CosyVoice、Seed-TTS28 等——越来越多地在主动绕开多 codebook 这件事:前半段用一个单层 semantic VQ(或 supervised phonetic token)做内容自回归生成,后半段用 flow matching 或 diffusion 在 mel / 连续 latent 上生成声学细节。换句话说,AudioLM 的 semantic + acoustic 两阶段范式没有消失,而是声学阶段从 SoundStream RVQ 换成了”连续表示 + 非 AR 解码器”。RVQ 那个”层级语义”被实质性地拆掉了:第一层的内容职责让单层 supervised VQ 接过去,后续层的声学细节职责让连续 decoder 接过去——多 codebook 的展开机制(delay pattern、local transformer)整套省掉。
这种设计的吸引力不只是”绕开 RVQ”。更深层的动机是最小化对 LM 架构的改动:每步一个 token、标准的因果自回归——和文本 LM 一模一样。这意味着可以直接复用LM的KV cache优化 等所有现成红利,不需要为音频专门重新设计 transformer 结构。声学复杂度被外包给一个独立的 flow matching head,主 LM 干干净净。这是离散路线对”tokens are flexible”这个论点最彻底的拥抱——既然 token 流可以是任何东西,那就让它和文本 token 流尽可能像,把音频的特殊性藏到 LM 之外的模块里。
所以更准确的判断是:RVQ 在 codec 设计这一层仍然主流,但在端到端生成系统这一层正在被”单层 semantic VQ + 连续 decoder”路线挤压。这条 hybrid 路线在 §4.2 还会再出现——它是”连续特征接管生成端”这条路线已经在产品里跑通的最强证据。
记住一点:RVQ 不只是个压缩技巧——它还白送给下游 LM 一个有用的层级:前几层偏语义、后几层偏声学,同一个 token 流可以按需消费。这是它在生成系统里难被替代的真正原因。
2.3 AudioLM 的 semantic / acoustic 范式
一句话概括这一节:AudioLM 把 token 分成 semantic + acoustic,是 2022 年的权宜之计——它的洞察(长程语义需要专门承担)是对的,但”两套独立 tokenizer + 三阶段 cascade”这个实现,正在被折叠进单一 codec。 下面顺着来龙去脉看它怎么来、又怎么一步步被收进一个 codec。
回到 2022 年的 Google Research。一群人在做一个具体的实验:拿 SoundStream 的 RVQ token,训一个标准的自回归 transformer,看能不能从一段语音 prompt 续写出更长的语音。
实验跑得很好——直到几秒钟之后。
模型重建音质完全没问题,每一帧听起来都像真人说话。但话题开始漂。说话人会突然跳到不相干的内容,偶尔退化成无意义的音节流——一种很奇怪的现象:声学上完全合理(每个音都像人发的),语义上完全脱轨(说的话开始没意义)。
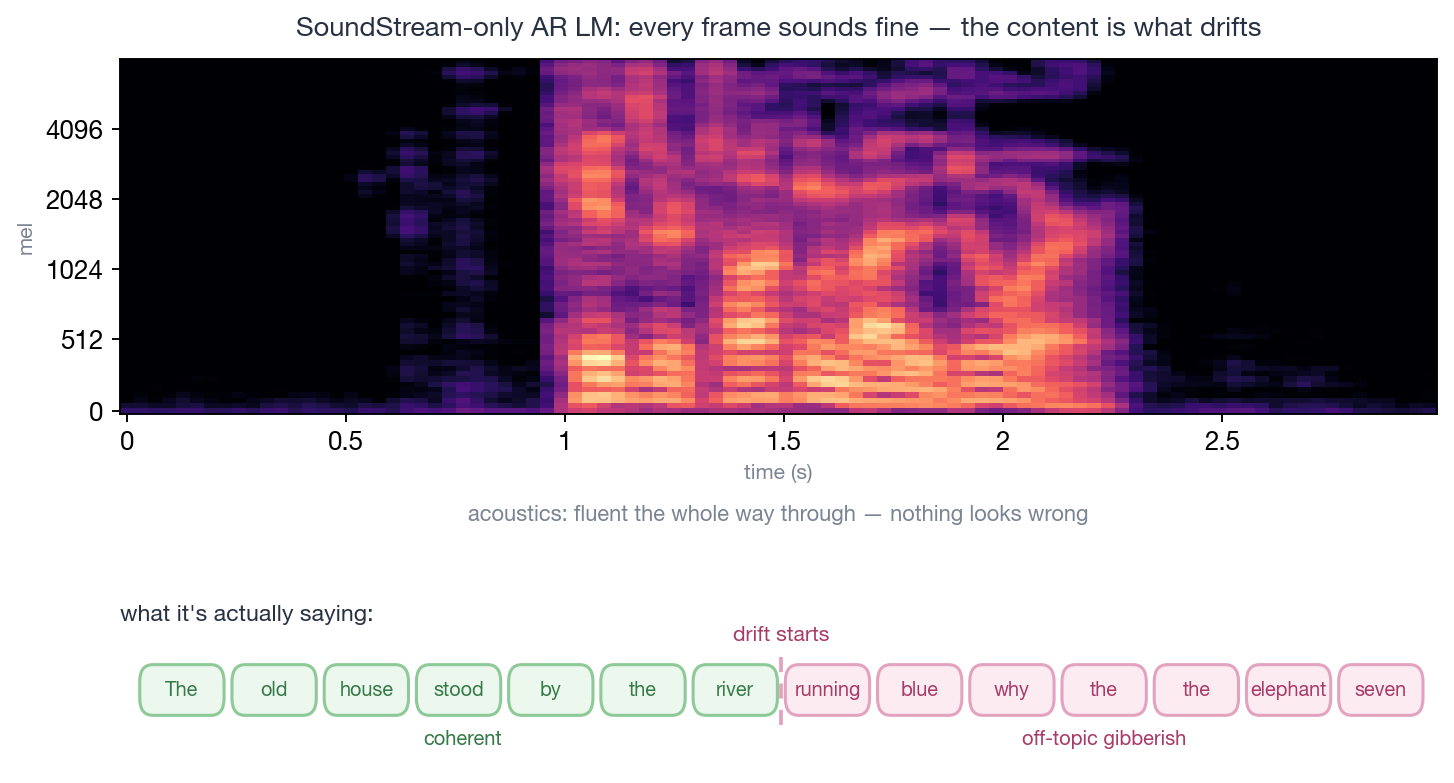
caption:”AudioLM 之前的 SoundStream-only AR LM 会出现的 drift。上面的频谱图说明声学上全程流畅、每一帧都像真人说话、看不出任何毛病;问题全在下面的内容——前半句还连贯(绿),从某个词开始就跑题、退化成无意义的词流(红)。声学没病、语义脱轨,这正是 drift 的本质。”
这件事不难诊断。SoundStream 是个 codec——它优化的是”如何还原波形”,不是”信号在讲什么”。它的 token 编码相邻帧之间高度物理相关的信息(相邻 50 Hz 帧的波形几乎一样),但没人告诉过它什么叫”一句话讲完”。在短距离上 LM 能学到 token 之间的局部连接(这一帧到下一帧),但在长距离上没有锚点告诉它”还在说同一件事”。
如果你只有这一种 token,就只能这样了。
AudioLM 团队的解法有点绕。 他们不去修 SoundStream,而是绕开它、再加一种 token:用 w2v-BERT(一个 self-supervised speech encoder)29的中间层特征做 k-means 聚类,得到一个第二种离散 token 流——他们叫它 semantic token。这个 token 在音素和词的线性探测上表现很好——也就是说它编码的是”声音在讲什么”。
然后他们的模型变成三阶段 cascade:
第一阶段,semantic LM——只看 semantic token,自回归生成内容。这条线短、长程稳定,相当于”先想好要说什么”。第二阶段,coarse acoustic LM——给定 semantic token 作为 condition,预测 SoundStream RVQ 的前几层(决定音色、韵律)。第三阶段,fine acoustic LM——给定 coarse 作为 condition,预测剩余层(细节)。最后用 SoundStream decoder 还原波形。
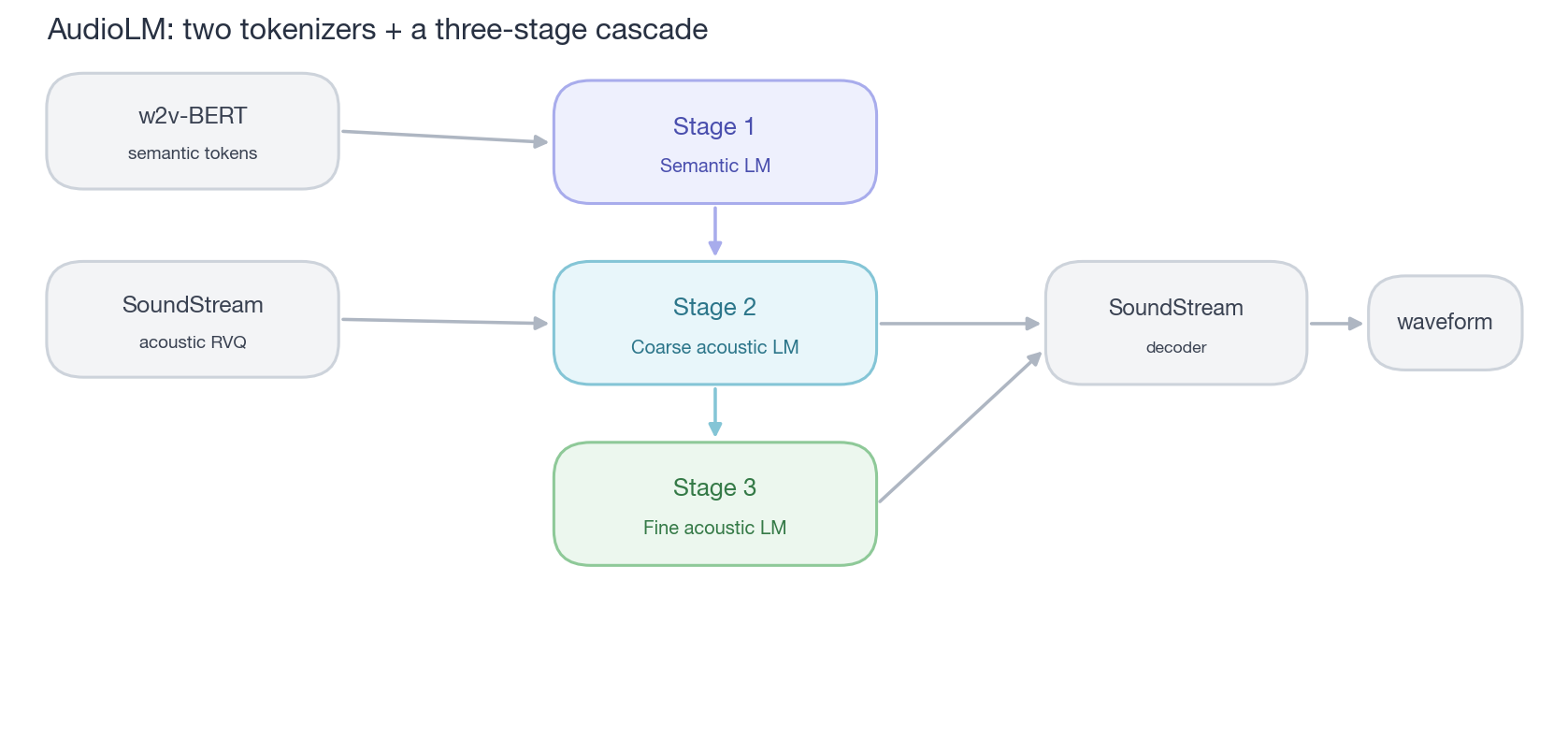
caption:”AudioLM 的 cascade——两种 tokenizer + 三个 LM(橙→蓝→绿三阶段)。复杂但有效:长程语义由 semantic LM 锚住,声学细节由 acoustic LM 填充。”
效果显著。AudioLM 可以生成 30 秒甚至更长的连贯英语 babble——是 2022 年最长的自由语音生成。Bark、MusicLM、VALL-E 等后续工作都从这个范式里借了灵感。它成了那一两年的 standard recipe。
但这个 recipe 有点奇怪。
视觉里没有等价物。 没人会用一个 “semantic VQGAN” 加一个 “texture VQGAN” 然后做三阶段 cascade——VQGAN 的 token 就够了。为什么音频要这么麻烦?我能想到三层。
最根本的一层:图像的语义是静态的一个点,语音的语义是随时间展开的一条轨迹。生成一张图,语义自始至终只有一个——”一只猫坐在沙发上”,所有 token 服务于同一个静态场景,不存在”语义随生成推进而演化”这回事。语音不一样:每一秒说的内容都在向前走,前半句决定后半句、这句话决定下句话——生成音频的同时必须持续做语义规划。视觉 LM 不需要长程语义稳定性这个能力,因为它的”长程”上根本没有语义在流动;音频 LM 必须有,否则就是我们看到的 drift。
第二是序列长度。一段 30 秒音频展开后上千 token,对 LM 来说是个长上下文挑战;视觉的 16×16 latent 远比这短,attention 容易稳。音频需要一个长程锚。
第三是内容-声学的物理耦合。某些声学上局部差异较小的 token 变化(细微的元音质量差、辅音 voicing 差异等)可以对应完全不同的词义;反过来,大量明显的声学差异(说话人、语速、情绪、混响)却完全不改变文本语义。Token 和”信息”之间不是双射。在这种深度耦合的信号上训 acoustic-only LM,它没办法自己长出”语义稳定性”——因为信号里根本就没把”语义”维度独立出来。
所以 AudioLM 加 semantic token 这件事,本质是给一个本来没有语义维度的 token 流,外挂一条专门承载”语义轨迹”的通道——把图像生成里根本不存在、而音频生成必需的那个能力,用工程方式补出来。
这三层背后其实是同一条信息论原理。把音频按条件熵劈开:一半低熵——内容 / 语义,被上下文几乎钉死;另一半高熵——音色、相位、纹理这些”给定内容仍然随机”的声学细节(也正是语义特征被训来扔掉的那部分)。而自回归模型每一步的不可约损失,恰恰就是条件熵 \(H(z_t \mid z_{<t})\):低熵那半 LM 预测起来又稳又准(文本 LM 好训是同一个理由——文本就是一个条件熵极低的表征),高熵那半硬塞给 AR 去逐帧”预测”,要么学不动、要么 drift——SoundStream-only 那次翻车的数学根源就在这。所以 AudioLM 加 semantic token,本质是把这个熵分解显式做出来:低熵、可预测的那半交给 LM 去 predict,高熵、随机的那半交给声学模型去 generate——predict the predictable, generate the rest。值得强调的是后半句:高熵细节不是被”预测”准的,是被一个随机生成器”采样”出来的——硬要 AR 去无损预测它,本就是用错了工具。
这条原理比 AudioLM 本身活得久:后面无论是把分工折叠进单一 codec(RVQ 第一层扛语义、残差层扛声学),还是连续路线的”语义 latent + 生成式 decoder”,做的都是同一个熵分解,只是换了实现。所以下面要拆的从来不是这条原理,而是它 2022 年那个笨重的实现。
如果你跟踪 2024-2025 的 audio codec / audio LM 工作,会发现一个清晰的趋势:新工作几乎都在尝试用单一 codec 替代 AudioLM 的两 tokenizer 拼接。Mousavi et al. 的 survey(2025-09)甚至在引言里直接说,acoustic vs semantic 的二分法”不够用”——因为大量 acoustic codec 已经被证明能携带语义信息(Mimi、SpeechTokenizer、dMel),同时 semantic tokenizer 也被广泛用于生成任务(GSLM、TWIST 等)。两个 category 实际在重叠。所以他们直接抛弃了二分法,转用一个更细的五维度分类法。
这不是说 AudioLM 的洞察错了——”长程语义需要专门承担”这个直觉是对的。问题在于”承担”不一定要用两套独立的 tokenizer 和三阶段 cascade。它可以在一个 codec 内部完成。
具体做这件事的有四条路径,可以理解为”如何把 AudioLM 的两 tokenizer 折叠成一个”:
第一条是 distillation——让 codec 的某一层显式承担 semantic。SpeechTokenizer(Zhang et al., 2023)30第一次系统地这么做:训 RVQ 时加一个辅助 loss,让第一层 codebook 的输出和 HuBERT 特征对齐。结果是第一层”被迫”承担 phonetic 内容,后续层自由学 acoustic 细节。Mimi(Moshi 配套, Kyutai 2024)31把这条路推到更极致——12.5 Hz 帧率、WavLM distillation 进第一层、causal 卷积 streaming friendly、8 层 RVQ × 2048 codebook ≈ 1.1 kbps(明显低于 EnCodec 的 6 kbps 量级)。
第二条是 hybrid encoder——用两个 encoder 但融合成一个 codec。X-Codec / SemantiCodec3233 是代表:dual-encoder 一支吃 SSL 特征、一支吃 acoustic,融合后量化成单一 token 流。这条路在工程上比 AudioLM 简单(仍然只有一种 token 给下游 LM),但在 encoder 层面承认 “semantic 和 acoustic 信息源头不同”。
第三条是 supervised semantic——不蒸馏,直接用 ASR 监督。这条路值得多说几句,因为它和前两条有一个本质区别。
代表作是 CosyVoice 的 S3 tokenizer34(Du et al., 2024):拿一个 ASR 模型,在 encoder 中间插一个 VQ 瓶颈,整个模型用 ASR loss 端到端训练(CosyVoice 2 把 VQ 换成 FSQ,码本利用率更好)。Token 之所以 semantic,是因为它必须支撑后半段网络完成文字识别——监督信号直接来自转写文本,不需要 SSL teacher。
注意这个设计和前两条路的本质区别:S3 没有重建目标,它根本不是 codec。SpeechTokenizer / Mimi 仍然是 codec——有 decoder、有重建 loss,semantic 监督是叠加上去的,token 既要承载语义也要支撑重建。S3 是一个被量化的 ASR 中间层——它没有重建目标,被设计性剥掉的主要是 speaker 音色(内容和相当一部分韵律 / 节奏其实还留在 token 里),”从 token 还原波形”这件事完全外包给下游的 flow matching decoder。这也解释了 CosyVoice 为什么必然长成”token LM + flow matching”两段式:token 里根本没有音色,必须在 flow 阶段从 reference audio / speaker embedding 里补回来。
同路线里更接近 codec 形态的是 PAST(Har-Tuv et al., 2025)35——它保留完整的 codec 结构(RVQ + 重建 loss),在第一层 RVQ 上叠加 phonetic classification 和 ASR-CTC 辅助损失。可以理解为:PAST 是”codec + 监督语义”,S3 是”ASR + 量化瓶颈”——前者保留波形还原能力,后者干脆不做重建、把还原波形整个外包出去。两种取舍对应不同的下游形态:PAST 的 token 还能直接重建波形,S3 的 token 必须配一个生成式 decoder。
第四条最激进,是 disentanglement——把 latent 拆成多个并行 codebook 流。FACodec(NaturalSpeech 3 的 codec,Ju et al., 2024)36训出四个独立 RVQ 模块:content / prosody / timbre / acoustic detail,每个由不同的 loss 监督。TiCodec、LSCodec37、SoCodec、SD-Codec38 等是同一思路的不同变体——按时间不变(音色)vs 时间变化(内容)分、按说话人 vs 内容分、按声源类型分。这条路放弃了”隐式涌现层级”的简洁性,换来”每个 codebook 都可解释”的可控性。
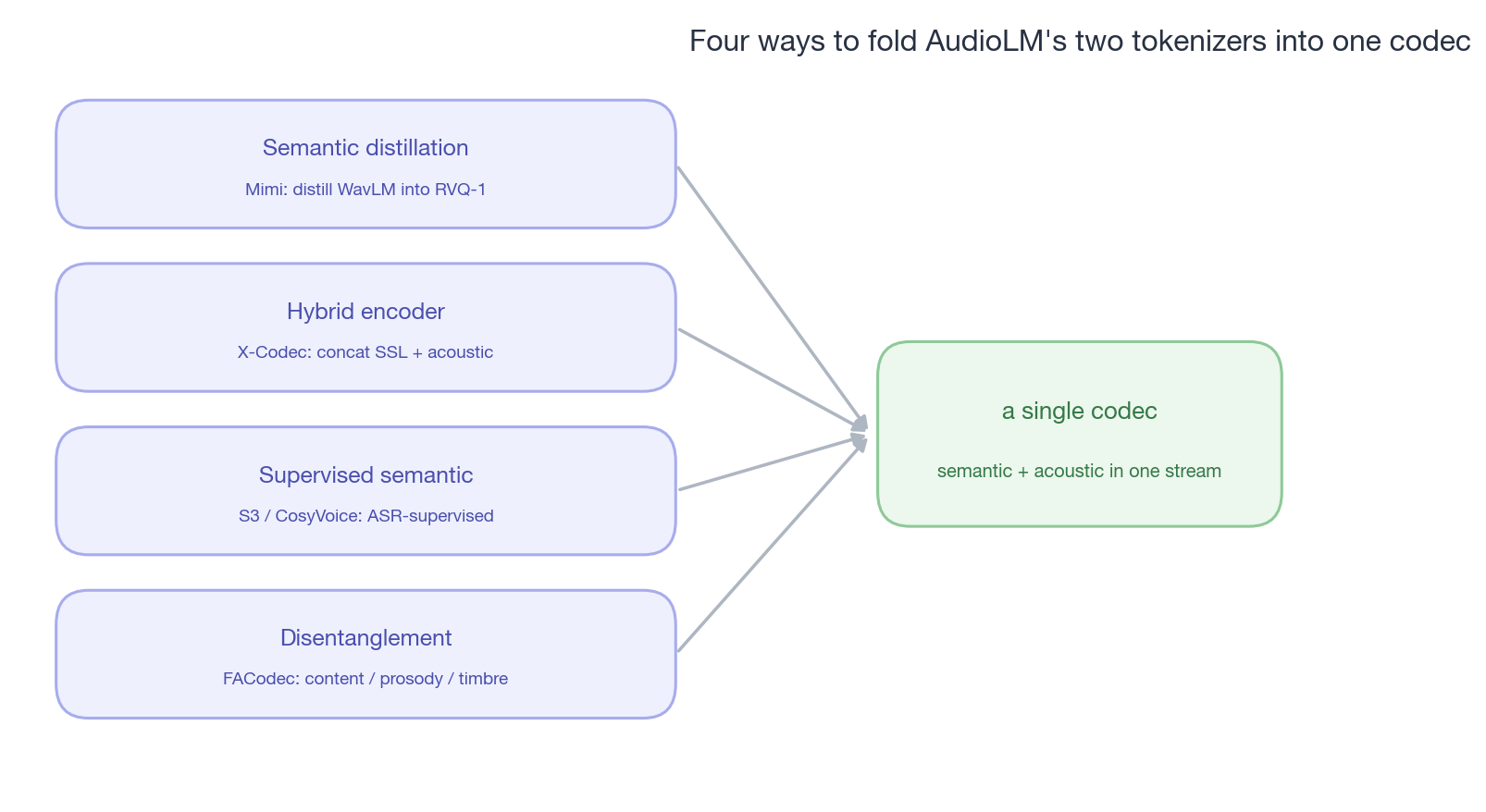
caption:”AudioLM 那个 cascade 的四种’平替’。路径不同但目标一致——把两个 tokenizer 折叠成一个,让下游 LM 不再需要 cascade。”
值得提一下:这四条路彼此并不排斥。FACodec 内部也用 distillation 和 supervised loss;Mimi 内部也有 streaming 设计。它们更像四种不同的”接入点”,让 SSL/语义信号渗入 codec 的不同位置。
2.4 下游建模的几种姿态
拿到一个 multi-codebook RVQ token 流,下游怎么吃?这是过去三年音频生成工程上变化最频繁的地方。这里有两根轴:一是怎么展开多层 codebook(AR 框架内的设计,下面四个例子体现了从”两套模型”到”单一模型”的演化),二是到底要不要自回归(AR vs 非自回归,本节后半段单独讲)。先看第一根轴。
VALL-E(Microsoft,2023)39。 核心问题:EnCodec 一帧 8 层 codebook,怎么自回归?回答简洁——只有第一层用 AR,后续 7 层用 NAR。AR transformer 在第一层 codebook 上自回归(这一层承载内容和韵律,AR 保证长程结构),NAR transformer 并行预测剩余 7 层。推理快(AR 部分序列比 flat 短 8 倍),顺手解锁 zero-shot voice cloning。代价是两个独立 transformer,难以共享。
MusicGen(Meta,2023)40—— delay pattern。 N 层 codebook 不在同一时刻平行预测,而是按 delay 错开:t=0 出 c0,t=1 出 c0+c1,t=2 出 c0+c1+c2…… 每个 step 同时输出当前所有层,但每层”时间”偏移了 i 步。等价于”AR over time + 部分 AR over codebook”。单一 transformer,序列长度 = T,没有 ×N 的代价。前 N-1 步质量稍差但实践上影响小。MusicGen 之后,delay pattern 成为多 codebook 自回归里非常有影响力的一类设计——MusicLM、Stable Audio 的部分实现、MAGNeT41 都有这条思路的影子;它和 depth transformer / AR+NAR / parallel prediction 等其他路线共同构成今天的设计空间。
UniAudio(Yang et al.)42。 这是第一个把多任务音频生成统一到单一框架下的工作——TTS、voice conversion、singing voice synthesis、sound generation、music generation、speech enhancement 等十几个任务共享同一个 transformer、同一套 token 词表、同一份训练目标。它对下游建模做的最重要贡献是 multi-scale transformer:在 multi-codebook RVQ 输入上,用一个 global transformer 在时间维度上做自回归,加一个 local transformer 在每一帧内部、codebook 维度上做自回归。global 看长程结构、local 看帧内层级分工,两者通过帧级别的 summary token 连起来。
这个架构 pattern 在 byte/字符 序列建模上有 MegaByte 这种先例,但音频多 codebook 上 UniAudio 是首个把它跑通的工作——多任务、规模到 ~1B 参数、训练数据约 100k 小时。它证明了一件之前没人验证过的事:用一个端到端 LM 同时承担多种音频生成角色是可行的,不需要给每个任务单独训练一个模型。这件事在后面 Moshi等系统里都有 echo。
Moshi(Kyutai,2024)。 走得更远,迄今最接近”语言模型范式音频”的系统。几个关键设计:
- Mimi codec:单一 codec,12.5 Hz 帧率(比 EnCodec 的 75 Hz 低 6 倍),第一层 WavLM distillation。这个 12.5 Hz 不是优化细节,是 game changer——它把一段 30 秒音频的总 token 数从一万八砍到三千,使得”用一个普通 LM 端到端建模音频”在算力上变得真正可行。
- Inner monologue:text token 和 audio token 在时间维度上交错——模型同时生成”它在说什么的文本”和”它真正说出的音频”,文本作为高层规划,音频作为实际输出。这个设计回应了 AudioLM 的 semantic/acoustic 分工,但用一个 token 流统一表达。
- Depth transformer:codebook 维度上有一个小型 AR——主 transformer 在时间步展开,每个时间步内部有一个小 transformer 顺序预测 8 层 codebook。Moshi 的贡献是把它和 streaming、inner monologue、low-frame-rate codec 组装成一个完整的实时对话系统。
- Full-duplex:用户和模型的音频流是两个独立 channel,模型同时听和说。这是产品形态对表征的反推——只有 streaming codec + streaming LM 才能做到。
CosyVoice / Seed-TTS:离散+连续混合。 最新一代 TTS 系统出现了一个有意思的分化:前半段离散、后半段连续。前半段用 semantic-rich token(SSL 量化或 distilled codec 的第一层)做自回归(继承 LM 范式:可控、in-context learning、zero-shot);后半段把离散 token 当作条件,用 flow matching 或 diffusion 在连续 latent / mel 上生成声学细节(继承连续路线:质量高、采样稳)。这是个值得专门展开的现象——它说明业界已经接受了一种生成管线内部的分工:用离散 token 扛 AR / 内容规划(吃 LM 的可控、in-context、zero-shot 红利),用连续 flow / diffusion 扛声学细节(吃生成质量、采样稳定)。这正是 §2.3 那个 “predict the predictable, generate the rest” 熵分解的工程化身,第 4 节会作为收束全文的关键论点。
第二根轴:离散 token 不一定要自回归生成。 前面四个设计都在 AR 框架里打转,但离散 token 还能用非自回归的方式生成——一次并行预测所有位置、再迭代 refine 几步。DiffSound43(Yang et al., 2022)是音频上最早的离散扩散:在 VQ-VAE 的 mel token 上做 discrete diffusion,一步预测全部 token、再逐步修正,比 AR decoder 快数倍。SoundStorm44(Google, 2023)把 MaskGIT 那套 confidence-based 并行解码搬到 codec token 上,质量追平 AudioLM 的 AR 生成、速度却快两个数量级(30 秒音频 0.5 秒出)。MAGNeT、NaturalSpeech 336 的 factorized diffusion 也属于这一类。这条轴的取舍很清晰:用并行/迭代换速度——几步 refine 就出结果,不像 AR 要走 T 步;代价是非因果(生成时要看到整段序列),所以做不了 streaming、也吃不到文本 LM 那套 next-token 红利。它和连续路线的 diffusion 其实精神相通——离散 token 借用了扩散的”迭代 refine”生成机制,这也是离散和连续边界模糊的一个例子。
演化方向是清晰的。 把 VALL-E(两套模型)、MusicGen(delay pattern + 单 transformer)、Moshi(单 codec + 单 transformer + streaming)放在时间线上看,趋势非常明显:越来越简化,越来越统一,越来越像”普通 LM”。这也回应了 Sander 在原文里说的 “tokens are flexible”——一旦表征变成 token,LM 的所有工程红利(KV cache、speculative decoding、长上下文优化、in-context learning)就直接可用。这是离散路线在产品落地上最大的不可替代优势。
2.5 离散路线的”可建模性”工具箱
这一节值得单独拎出来,因为它是离散路线最重要的一条暗线——比任何单个 codec 都值得记住。把 §2.2–2.4 一路看下来会发现:codec 这些年真正攒下的,不是更高的重建质量,而是一整套”让表征对下游生成模型更好学”的手艺。 Sander 原文把这类操作叫 regularising for modelability——为可建模性而做的正则化。这恰恰是 2023 年之后的 codec 和第一代纯压缩 codec(SoundStream/EnCodec 那批)最本质的分水岭:前者每一个设计选择瞄准的都不是”还原得多准”,而是”第二阶段好不好学”。
音频离散这边的工具,甚至比视觉那边还多:
- 帧率——最重要的旋钮。Mimi 把 12.5 Hz 当核心卖点、TADA 压到 2-3 Hz:序列长度直接决定 LM 学不学得动。帧率每减半,下游 LM 的上下文负担减半。
- 容量配置——codebook 数不是越多越好:更多 codebook 提升重建,却引入更多冗余维度、加重下游建模,在 ASR / SE / SS 这类任务上常常反而拖累下游。容量要和下游消费方式 co-design,而不是照着重建指标调。
- 语义监督——distillation / supervised loss / disentanglement(§2.3 的四条路):让 token 的结构对 LM 友好,把”decoder 的私人语言”翻译成”公共语言”。
- 让 token 自带自回归先验——我们在 ALMTokenizer45 里提出的 AR prediction loss:在 RVQ latent 上挂一个轻量的连续 AR transformer,用前几层 codebook 的特征去预测后一层(MSE 优化),把”下游 LM 能不能预测准”直接写进 codec 的训练目标。动机是个很具体的观察——RVQ 第一层偏语义、最好学,残差层偏声学、明显更难被 AR 拟合,这个 loss 专门去压低残差层的预测难度。代价也诚实:它会稍微拉低重建,却换来第二、三层 token 预测准确率显著提升、下游 TTS 的 WER 下降。这是本节主题最干净的一个例子:牺牲一点重建,换下游更好学。
- 展开方式——delay pattern、local transformer、AR+NAR 分工:同一个 token 流,排布方式不同,可建模性天差地别。表征设计不止于 encoder,token 怎么”喂”也是表征设计的一部分。
- 生成式 decoder 吸收量化误差——把 decoder 做成生成模型而非确定性还原:LaDiffCodec 的 diffusion decoder46、CosyVoice 的 flow 段都是这个思路。离散 token 必然有量化损失,确定性 decoder 会把损失原样还原成 artifact,而生成式 decoder 把 token 当条件、采样出一个合理的音频实现——这等于放宽了对上游 token 的精度要求,下游 LM 不必预测得分毫不差。这正是连续路线那套”生成式重建”被借进离散路线的接口。
把这六件工具排在一起,会看到它们指向同一个动作:调的全是”下游好不好学”,没有一件是冲着重建质量去的。 这正是”为下游设计表征”这个自觉在工程上的全部展开——§3.3 会看到连续路线手里有一套几乎镜像的工具,回答的是同一个问题。
3. 连续路线:Audio as Latents
离散路线的故事是”把音频变成另一种文本”。连续路线的起点朴素得多——把图像生成的工程模板搬到音频上。但搬运的过程中发生了两件当初没人预料的事:latent 自己长出了语义,自回归挣脱了离散。这一章讲这两次转折,以及它们把连续路线从”保守的备选”变成了统一接口之争的另一极。
3.1 第一阶段:搬运视觉模板
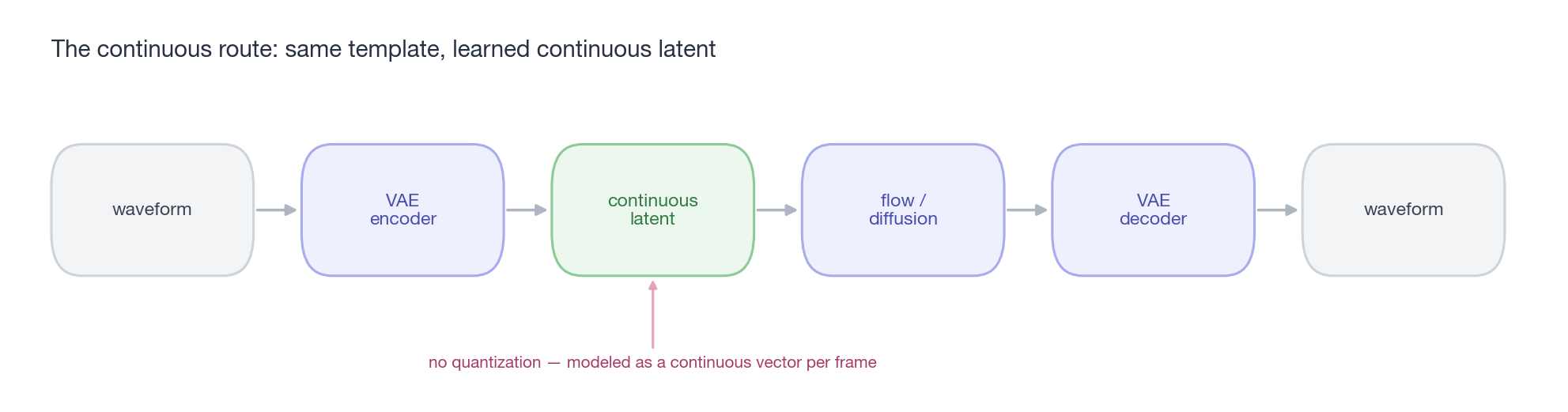
caption:”连续路线的工程模板,几乎是 §1 那张 LDM 图的搬运:波形 → VAE encoder 压成连续 latent → 在 latent 上跑 flow / diffusion 生成 → decoder 还原波形。和离散路线唯一的区别,是中间那层 latent 不量化——每帧是一个连续向量,而不是一个码字。”
先把一个常见的误解纠正掉:音频的序列 latent 模型出现得非常早。VRNN(Chung et al., NeurIPS 2015)47就在 TIMIT / Blizzard 上做每个时间步一个 latent 的语音建模,SRNN(Fraccaro et al., 2016)48跟进,FHVAE(Hsu, Zhang, Glass, NeurIPS 2017)49用分层序列 VAE 做出了说话人/内容解耦。”保留时间网格”这个洞察,音频比视觉的 VQGAN 早了六年——因为音频的时序性明显到没人会想把整段语音压成一个固定向量。
真正卡住连续路线的不是网格,是糊。纯 VAE 的高斯似然有个有名有姓的病:over-smoothing——参数化 TTS 时代被反复研究过(Toda & Tokuda 200750 的 Global Variance 补偿就是在修它),生成的频谱轨迹是所有合理实现的平均,听感发闷发哑。用 §1.1 的语言说:高斯似然在 texture 上强行回归均值,而texture 的均值不是任何一个合法的 texture。
解药和视觉殊途同归:把对抗训练放进 decoder。这一步的标志是 VITS(Kim et al., ICML 2021)51——它的全名经常被忘掉:Conditional Variational Autoencoder with Adversarial Learning for End-to-End TTS。Frame-level 序列 latent + flow prior + 对抗 decoder,成为 2021-2023 部署最广的 TTS 架构之一。所以”VAE 在音频上没成功”是个伪命题——VAE 只是需要一个 GAN 帮它把纹理画清楚,这和视觉里 KL-VAE 按 VQGAN 配方训练是同一个教训。
然后是搬运的成熟期。扩散模型先在波形上试(WaveGrad、DiffWave,2020——太慢),再搬到 mel 上(Grad-TTS、DiffSinger,2021),最后落到学出来的连续 latent 上:Make-An-Audio(Huang et al., ICML 2023)52做 text-to-audio 通用音频生成,Stable Audio(2023-24)53把 SDXL 模板搬到音乐54——卷积 VAE + DiT,约 64 维、21.5 Hz 的连续 latent;Music2Latent(2024)55用 consistency 思想做出单步解码。生成端则被 flow matching 接管:Voicebox(2023)56开了头,Matcha-TTS57、SimpleSpeech 1/2(Yang et al., 2024)58、E2-TTS、F5-TTS(2024)59跟上——训练目标更直接、采样步数更少。这一批里我想多说一句我们自己的 SimpleSpeech,它有两个值得停一秒的点。一是它的 diffusion / flow 跑在 SQ-Codec 的 scalar latent 上——这个 latent 量化过(FSQ 式标量量化),却被当作连续空间来建模,一个”离散的表征、连续的建模”的组合——离散与连续的边界,本来就没那么清楚。二是它最早把 phone-level duration predictor 去掉——只给一个 sentence-level 的总时长,对齐交给模型自己在 flow matching 里学。这一步把 TTS 传统流水线里最麻烦的零件之一直接删了。
这其实开启了一整类 NAR flow matching TTS 的共同范式:管线纯粹到几乎没有零件。E2-TTS 把这个思路推到极致(连 grapheme-to-phoneme 也省了,纯字符填充 + flow matching 学对齐),F5-TTS 再补上推理效率和稳定性。训练数据也简单到极致:只要 ⟨text, audio⟩ 配对,不需要音素标注、不需要时长标签、不需要任何中间 token。text + reference audio 进、波形出,中间什么离散结构都没有,质量却站进 TTS 第一梯队。这种”少即是多”本身就是连续路线的一张王牌——它把音频生成的数据和工程门槛压到了和训练一个普通 seq2seq 差不多的水平。
这个阶段的方向和离散路线完全平行:信号压得越来越小、每帧信息密度越来越高(24 kHz waveform → 100 Hz mel → 50 Hz codec latent → 21.5 Hz VAE latent)——Sander 三角的 rate 往下压、modelability 往上提。
3.2 Latent 的语义转向:和离散路线对上了
搬运模板跑通之后,连续路线撞上了一个和离散路线完全相同的发现:纯重建目标训出来的 latent,对生成模型不是最友好的。
证据先从视觉来。REPA(Yu et al., 2024)60发现把 DiT 的中间特征对齐到 DINOv2,训练收敛能快一个数量级以上;RAE(Representation Autoencoders, 2025)61走得更绝——把 VAE 整个扔掉,直接用 frozen 的 DINOv2 这类理解模型的特征当 diffusion 的 latent space,重建交给一个单独训练的 decoder。语义结构让 latent 更好拟合,这在视觉已经从技巧上升为原则。
这个”原则”其实有相当硬的理论根据,值得说穿——否则它和玄学没区别。扩散 / flow 模型归根到底在估计一个 score 场 \(\nabla\log p_t\),而估计 score(或密度)有一条绕不过去的 minimax 下界:估一个 β-光滑、d 维的目标,误差率约为 \(n^{-\beta/(2\beta+d)}\)——维度 d 一高,误差就指数级恶化,这就是维度灾难。但关键结果(Oko–Akiyama–Suzuki 证明扩散能达到这个 minimax 率62、De Bortoli 给出流形假设下的收敛保证63)说:如果数据其实活在一个内在维度 d′ ≪ d 的流形上,收敛率只由 d′ 和光滑度 β 决定,与 ambient 维度无关。
这就把”语义让 latent 好建模”翻译成了两个可量化的旋钮。其一,语义结构压低内在维度 d′:语义特征高度低秩——LoSATok 实测 DashengLM 那个 1280 维特征的 effective rank 只有 257,这个数字正是 d′ 的一个直接的经验度量。其二,语义组织让流形更平滑、score 场的 Lipschitz 常数更小(扩散的采样/收敛界显式依赖这个常数),同样的网络容量就能把 score 拟合得更准。所以 REPA 收敛快一个数量级、WavCube / LoSATok 把维度压下去就管用,不是经验巧合——它们是在直接拧 d′ 和 β 这两个出现在估计误差率里的量。
音频在同步发生同样的事,而且样本不止一个。DashengTokenizer 最清晰:frozen 的语义 encoder 特征为底、一个线性层注入声学信息,得到的连续 latent 同时在 22 个理解任务和 TTA/TTM 生成上超过基线——它在生成端的对照组正是”标准 VAE latent”,而它赢了。MingTok-Audio(Ming-UniAudio)64从另一头做同一件事——给一个低维 compact latent 用 semantic module(Whisper 蒸馏、对齐 LLM 语义空间)抬出高维的语义 latent,让下游吃到的表征自带语义结构(它”保留两个视图”的具体做法 §3.5 会细看)。两个工作一个从语义端注入声学、一个给低维 latent 抬出语义,方向相反,落点都是”让连续 latent 自带语义结构”。2026 年这条线在音频上又往前迈了一步。WavCube65、LoSATok66 几乎同时给出同一个诊断:直接拿高维语义特征(WavLM 1024 维 / DashengLM 1280 维)喂 DiT 会崩——维度太高、分布 off-manifold(WavCube 实测 1024 维直接进 DiT,zero-shot TTS 的 WER 高到 110%),但这些特征其实是低秩冗余的(LoSATok 测出 DashengLM 的语音语义特征 effective rank 只有 257)。于是两者都走 compress-then-enrich:先把语义压进一个 128 维 bottleneck,再注入声学细节,并用一个语义锚定 loss 把压完的 latent 钉回原语义流形、不让它漂走。换来的连续 latent 既能做理解(逼近甚至超过 WavLM / HuBERT),又对 DiT 友好、收敛更快。这等于在音频上把 REPA / RAE 那条”语义让 latent 好建模”再推进一步:不只要语义,还要够低维——正好提前回应了 §3.5 那个”高维语义 latent 难建模”的张力。
这件事和离散路线的语义转向(§2.3 那四条 distillation / supervised semantic 路线)是同一个发现的两种形态:离散在给 token 注入语义,连续在给 latent 锚定语义——两条路线在”表征需要语义结构才好建模”这一点上殊途同归。
3.3 连续路线的“可建模性”工具箱
语义锚定其实只是连续路线”提升可建模性”工具箱里的一件。和 §2.5 那个离散工具箱对照着看,连续这边的家伙事儿也攒齐了:
- 轻 KL——继承自视觉 LDM 的传统:KL 权重小到不像变分推断(1e-6 量级),它的真实职能是控制 latent 的 scale 和平滑性,让 diffusion 的噪声调度有的放矢。
- 有界标量空间——我做 SQ-Codec 时把 latent 钉死在 [-1,1] 的有限格点上:有界、近均匀、各维独立,正是 diffusion / flow 最好学的分布形状(§3.1 提过 SimpleSpeech 直接在它上面跑 diffusion)。这三条性质各自对应一个理论上的好处:各维独立让联合分布因式分解成 \(\prod_i p_i(z_i)\),d 维估计难题塌缩成 d 个一维易题——直接绕开 §3.2 那个维度灾难(有定理:扩散估计器能自适应这种因式分解结构、拿到 minimax 最优率67);有界让 score 不会在尾部炸、反向采样路径短而稳;近均匀是紧支集上的最大熵分布,既把码字利用率拉满,又没有”稀有但重要”的模式让生成模型漏采。注意量化在这里的身份转换:不是为了产出离散 token,是为了修剪分布——把分布修剪成”满维、均匀、独立”这种好建模的形状,恰好和语义路线”压到低维薄流形”是方向相反的两种逃逸。
- 语义锚定——刚讲过的 REPA / RAE / DashengTokenizer。
- 维度控制——VibeVoice 的低维 VAE feature vs Dasheng 的 1280 维语义特征:维度是”可建模性”和”语义丰富度”之间的硬 trade-off(§3.5 会展开 RAE 那个 width > latent dim 的教训)。
- 让 latent 自带生成先验——SAME68 的 generative alignment loss:在 autoencoder 的 latent 上联合训一个小型 diffusion / flow-matching head(warmup 后让梯度回流进 encoder),把 latent 几何直接塑形成”对 diffusion 友好”的形状。这正是 §2.5 那条 AR prediction loss 的连续镜像——离散那边联合训一个 AR 模型让 token 更可预测,连续这边联合训一个 diffusion head 让 latent 更可生成,SAME 自己也点明”离散常这么干,连续侧还很少见”。
- 平滑性 / scale 约束——连续 latent 没有 codebook 把取值钉在合法点上,所以更依赖训练时对取值范围和邻域连续性的约束:轻 KL 是其一,spectral norm、tanh 压缩也常见,SAME 干脆用一个 soft-normalisation bottleneck(可学 affine + EMA std 归一)替代严格 KL-VAE 来管 scale。还有一招更直接——SAME 训练时往 latent 注入比推理时大得多的高斯噪声(5e-2 vs 1e-3),主动把流形抹平,让 decoder 对下游 diffusion 的预测误差更鲁棒。目的都一样:让相邻帧的 latent 变化平缓,flow / diffusion 的 vector field 才好拟合。
把两个工具箱并排放,对称性几乎是镜像的:离散用语义蒸馏、连续用语义锚定;离散调帧率、连续调维度;离散用一个联合训练的 AR 模型塑形 token、连续用一个联合训练的 diffusion head 塑形 latent。两条路线在用不同的工具回答同一个问题:怎么让表征对第二阶段好学。 唯一一件两边共享、不分家的工具是生成式 decoder(前面提过的 LaDiffCodec / CosyVoice flow 段那一类)——它从输出端放宽对第二阶段的精度要求,离散连续都受益,也正因如此它成了 hybrid 系统的黏合剂。
3.4 流式:从 NAR 的天花板到连续自回归
搬过来的模板有一个搬不掉的属性:纯粹的 diffusion / flow matching 是 non-autoregressive 的——它对整段 latent 做迭代去噪/ODE 积分,生成开始前需要知道序列的全貌。这在单向 TTS 里完全不是问题——文本给全、语音生成全,F5-TTS 的质量已经证明69了这条路的上限。但它结构性地做不了一件事:边听边说。
于是连续路线的优劣在这里呈现出一种极化。优势侧都是结构性的:没有量化梯度问题(straight-through、commitment loss 这些 VQ 的工程麻烦全免)、和视觉工程栈天然兼容(DiT、各种 sampler、consistency 蒸馏直接复用)、信息保真没有 codebook collapse 这类瓶颈。顺带澄清一个常见误读:NAR 不等于”慢”——flow / diffusion 多步迭代但每步对整段并行,离散 AR 每步轻但严格串行,wall-clock 互有胜负,offline 速度从来不是连续路线的短板。短板侧同样结构性:LM 工程栈接不上、token-level 编辑做不了,以及最致命的——实时双向通信做不了。在单向生成里优势全兑现,在实时对话里短板全暴露,而后者恰好是音频最有商业价值的形态。
如果连续路线只有纯 NAR 这一支,故事到这里就结束了。但“流式”恰恰逼出了连续路线最有意思的一次自我突破——把生成过程自回归化。
这里要先拆掉一个流传很广的等式:自回归 = 离散 token,连续 = NAR diffusion。这是错的——自回归只是对联合分布按时间做因式分解,它对”每一步输出什么形态”没有任何要求。每步一个离散 token 可以,每步一个连续向量也可以。大家默认 AR 配离散,只因为 softmax 太好用:离散词表 + cross-entropy 直接给一个完整条件分布,温度、top-k 全是免费的。换到连续输出,最朴素的 L2 回归会立刻撞墙——回归学到的是条件均值,而”两个合理未来的平均”往往不是合理的未来(同一句话升调降调都对,L2 给你一个中间的鬼调子),加上连续空间没有 codebook 吸附误差,长序列会逐步崩掉。条件分布的多模态性 + 误差累积,才是”AR 必须离散”这个印象的真正来源。
但这两个问题都有解,核心思路一致:别用回归,给每一步配一个真正的分布头。三代形态:
- 方差采样——MELLE(Microsoft, 2024)70AR 预测连续 mel 帧时预测均值和方差再采样,最朴素但已让 continuous AR TTS 跑通。
- 混合分布头——视觉的 GIVT71 让 transformer 输出 GMM 参数采样下一个连续向量,表达力强一档。
- Diffusion / flow head——MAR(Li et al., 2024,视觉)72、VibeVoice、DiTAR(ByteDance, 2025)73:LM 的 hidden state 当条件,驱动一个小型 diffusion / flow 模型采样下一帧。表达力上限最高,代价是每步多跑几次 head。
关键在于看清一件事:前面说的那些”NAR 流式补救”——chunked sampling、block-wise causal diffusion——其实就是这个范式的粗粒度版本。把序列切成块、块间因果、每块内部用 diffusion 生成,本质上就是 chunk-level 的连续自回归。所以”NAR 怎么改才能流式”和”连续 AR 怎么做”不是两个问题,是同一个问题的两种粒度。一旦想通这点,连续路线的 streaming 困境就不再是死局——它只是纯 NAR 那一极输了,把生成沿时间因式分解(无论叫 chunked diffusion 还是 continuous AR)这一极,结构上就是 causal、就能边听边说。
这个范式在分类学上的位置很微妙:骨架是 LM(causal、KV cache、每步一个 position),血肉是连续的(没有 codebook、没有量化损失)——正是前面”路线二”说的”AR LM + flow head 预测连续特征”的应用形态。它的工程生态(KV cache 优化、采样控制、长序列稳定性)相对离散 AR LM 还年轻,但路是通的,而且最近一两年成熟得很快:VibeVoice、DiTAR 在单向生成上把质量做了上去,而 TML-Interaction-Small(2026)更进一步——把这套”chunk-level 连续 AR”做成了 200ms 微回合的全双工实时系统,dMel 输入 + flow head 输出,边听边说,全程没有一个离散 token。这恰好兑现了本节开头那句拆等式的话:streaming 不是离散的专利,把连续生成沿时间切块因式分解,一样能边听边说。连续路线并没有结构性地输掉 streaming——它只是还在补工程债,而且补得比预期快。
3.5 拼图还差一块:高维语义 latent 的流式建模
到这里可以盘点一下连续路线的家底了。它需要三样东西凑齐才能竞争统一接口:语义化的 latent(3.2,理解端要能直接读)、流式的骨架(3.4 的连续 AR,实时场景要能进)、精准的分布头(3.4,质量要扛得住)。三样各自都有了雏形——但把它们拼在一起,恰恰是难点所在。
问题出在维度上。DashengTokenizer 的 latent 是 1280 维——语义丰富、理解端表现优异,但放进连续 AR 的流式场景,每一步 flow head 都要在 1280 维空间里精准刻画条件分布。RAE 在视觉里给了一个不太舒服的提醒:flow matching transformer 的宽度必须超过 latent 维度,才能拟合好高维特征——他们的解法是加一个宽而浅的专用 head。换到音频流式场景,这意味着 1280 维的语义 latent 需要一个 1280+ 宽的分布头每帧都跑——”轻量 head”的假设直接破产。VibeVoice 选低维 VAE feature 正是在回避这个问题——但低维又牺牲了语义的浅层可及性,理解端要另外想办法。
§3.2 提到的 WavCube / LoSATok 正是冲着这根边来的——把 1024 / 1280 维语义特征压进 128 维,既保住语义又压低建模代价,看起来两头都要到了。但要看清它们验证到哪一步:好成绩都来自 DiT 这种 NAR 生成,而这里说的流式连续 AR——把低维语义 latent 接进一个每帧都要跑、还得 causal 的 flow head——目前仍然没被验证过。也就是说,维度难题在 offline / NAR 这一侧正在被解,在流式这一侧还是空白。
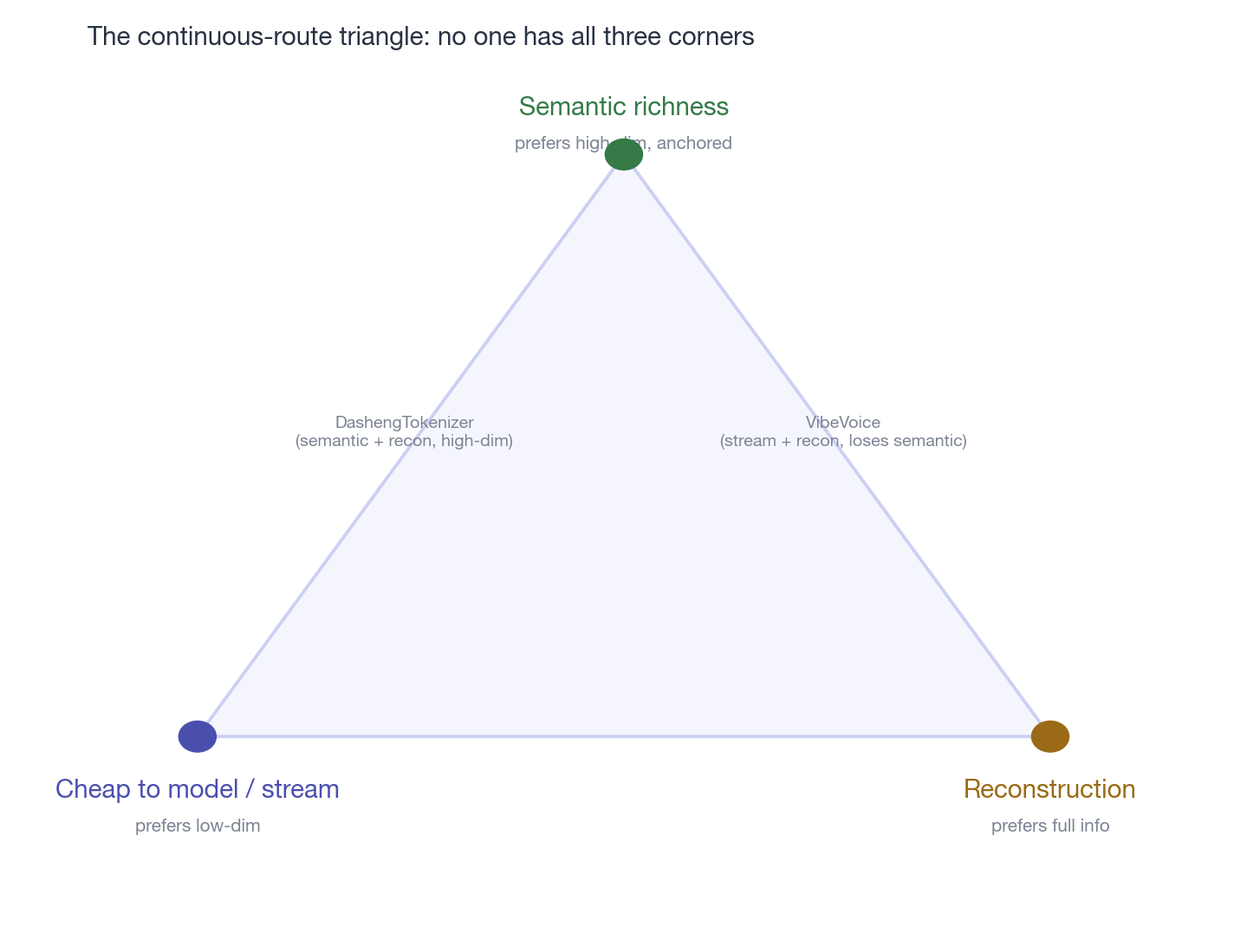
caption:”连续路线的三角——语义丰富度、流式建模代价、重建质量,三个角彼此拉扯。DashengTokenizer 占了语义 + 重建(代价是高维)、VibeVoice 占了流式 + 重建(丢了语义);到目前为止,没有哪个连续表征能一次拿全三个角。”
所以连续路线的核心设计问题可以总结成一个三角:语义丰富度(偏好高维、语义锚定)× 流式建模代价(偏好低维、分布简单)× 重建质量(偏好信息保真)。到不久前为止,还没有哪个连续表征同时拿到三个角——DashengTokenizer 拿了语义和重建(代价是高维)、VibeVoice 拿了流式和重建(代价是丢语义);刚说的 WavCube / LoSATok 用低维压缩把三个角的性质凑齐了,却只在 NAR 验证过,流式 AR 那一角还悬着。
§3.2 提到的 MingTok-Audio 在这里值得看仔细——因为它恰恰说明这个三角有多难绕开。它是个 VAE-based 连续 tokenizer,50 Hz、causal 可流式;encoder 先出一个低维 compact latent(设计目标在 32/64 量级),再用 semantic module 把它抬成一个高维的语义化 latent,下游 LLM 吃的、decoder 重建用的都是这个高维 latent。关键在于它并没有把语义压进低维——语义还活在高维那一端;它的策略是同时保留两个视图:compact latent 顾及效率、高维 latent 顾及语义。
这其实没有解掉三角,更像是把它换了个地方:你不再纠结”单个 latent 该高维还是低维”,而是要管两个 latent 之间的映射稳不稳、那个高维 latent 接进 per-token flow head 时是不是又回到了 Dasheng 那个”高维难建模”的老问题。说穿了,”一个统一连续表征”在仔细看之下,内部往往还是藏着一个 compact / semantic 的分工。
所以这个三角和前面两条路线的竞争是同一枚硬币:连续这条路要赢,就得有人真正把它解掉——目前的工作更多是在三条边之间挪动,还没有谁把三个角一次拿全。
不过还有一条更釜底抽薪的可能,藏在三角的一个隐藏默认里:我们一直假设输入和输出用同一个表征。 凭什么?理解端要”读懂”,偏好高维语义;生成端要”逐帧预测”,偏好低维好建模——而这两件事的代价是不对称的:读一个高维特征只是一次投影,便宜;让 flow head 每帧自回归地预测一个高维特征,才是真正贵的那头。那就别让它们共用一个 latent:输入端尽管用高维语义表征(反正只读不预测,高维几乎白送),输出端只预测一个低维 compact latent(只有它进 flow head,保持便宜),中间用一个 decoder 把低维输出补回波形。三个约束本来全压在同一个表征上,一旦输入输出解耦,语义的担子甩给输入、建模代价的担子留给输出,三角最紧的那根边就松了。这条路还没被系统地走通,但它可能比”造一个三个角全占的全能 latent”更现实。
这也回头解释了为什么”hybrid 离散+连续”会成为短期最现实的形态:离散路线在前半段保留 streaming / LM 基础设施的优势,连续路线在后半段保留生成质量的优势。两条路不是互相吞并,而是按产品需求分工——streaming 给离散,质量给连续。这种缝合短期内会稳定下来。
真正的悬念是中期:当连续 AR 的工程生态成熟、高维语义 latent 的流式建模被解掉之后,连续路线能不能反过来侵入实时场景,把离散路线压回更窄的利基?这件事第 4 节继续展开。
4. 升华:两条路在收敛,真正的争议在别处
§3 末尾留了一个悬念:当连续 AR 生态成熟、高维语义 latent 的流式建模被解掉,连续路线会不会反过来侵入实时场景?这一节给出我对这个问题的答案——并不会有清晰的”侵入”或”被吞并”。真正决定音频生成未来的,不是”离散还是连续”这个表面分歧,而是两条路之下更深层的几个结构性问题。
先说清楚两条路其实在收敛到同一组目标、甚至可以共存(4.1);再看这场收敛会落到什么样的统一接口上——更深的 RVQ,还是更轻的连续特征(4.2);然后是音频独有的”网格暴政”(4.3);最后把引子里那两个”真正的争议”收进一个统一的几何框架(4.4):Sander 的 rate-distortion-modelability 三角,在音频上要扩展成一个四面体。
4.1 离散与连续,正在收敛到同一组目标
核心观点:离散和连续不是在朝相反方向跑——它们都在做同一件事:在音频苛刻的序列长度和流式约束下,把表征做得更好建模。
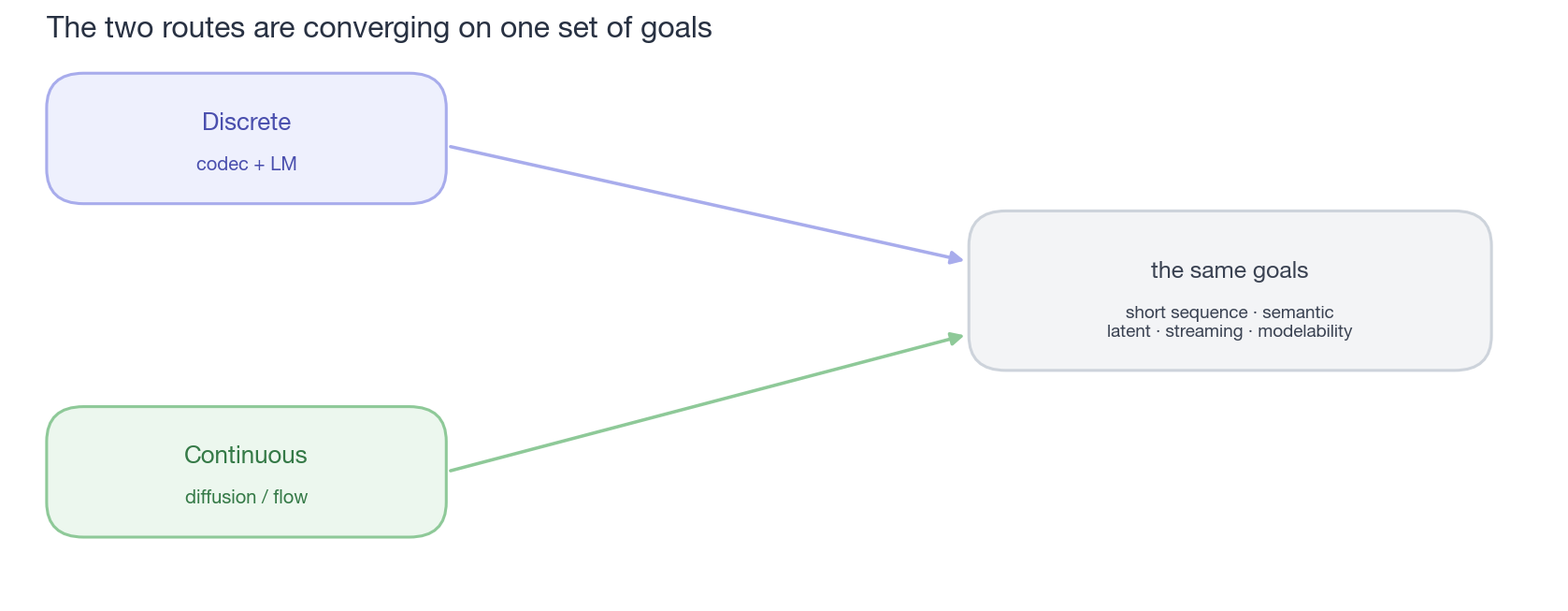
caption:”两条路,同一个终点。无论从离散(codec + LM)还是连续(diffusion / flow)出发,最后都在解同一组问题:更短的序列、语义化的 latent、流式、可建模性。表面的’离散 vs 连续’之争,其实是在向中间收敛。”
把前面三章铺的东西退远一步看,会发现一件容易被”离散 vs 连续”这个对立叙事盖住的事:两条路其实在朝同一组目标收敛。 不管你从哪一端出发,最后都在解同样的三个问题——
- 怎么让表征序列更短:离散这边压帧率(Mimi 12.5 Hz、TADA 2–3 Hz),连续这边压维度和帧率(VibeVoice 7.5 Hz)——目标都是让下游 LM 的上下文负担小到学得动。
- 怎么让表征更有结构、更可建模:离散靠语义蒸馏 / 层级监督,连续靠语义锚定(REPA / Dasheng / Ming-UniAudio)——本质都是把语义结构注进表征,让它对生成模型友好。
- 怎么平衡重建质量和可建模性:§3.5 那个三角,两条路面对的是同一个三角,只是从不同的角切入。
换句话说,离散和连续是同一个问题的两种坐标系,而不是两条对立的路线。它们的工具(§2.5 和 §3.2 那两个工具箱)几乎是镜像的,要解的难题也是同一批。
而且——它们不必互相取代,完全可以共存、相辅相成。 最现成的例子就是 CosyVoice / Seed-TTS 那种分阶段共存:前段离散 token 做内容规划(吃 LM 的红利),后段连续 flow 做声学细节(吃生成质量)。但共存不止于”分阶段”——更激进的可能是在同一个 LM backbone 上同时用两种表征:让模型既能吐离散 token(管 streaming、管和文本对齐),又能吐连续向量(管高保真生成),按任务在两种 head 之间切换。这条路还在早期,但它指向一个比”谁取代谁”健康得多的未来:离散和连续不是水火不容的二选一,而是一套表征系统里各管一段的两种工具。
这也是为什么本章接下来不再纠结”离散还是连续”——真正的争议在更深的地方。
4.2 统一接口会是什么——更深的 RVQ,还是更轻的连续特征?
前面铺了这么多,到了该下判断的地方。先看当前的事实格局。
理解端,连续特征领先。 在 ASR、emotion recognition、speaker verification 这些依赖”听懂”或”听清细节”的任务上,连续 SSL 表征(典型如 WavLM)对所有形态的离散 token 都保持着不小的领先——纯 acoustic codec(EnCodec、DAC)差距最大,semantic-distilled codec(SpeechTokenizer、Mimi)次之。低资源场景、复杂声学场景下差距进一步放大。
生成端,离散 token 起步更早、生态更厚。 AR LM 的全部工程红利(KV cache、speculative decoding、in-context learning)、zero-shot voice cloning 的成熟范式(VALL-E 系)、streaming 实时对话的早期完整系统(Moshi)——都先在离散 token 上跑通。但要注意,“边听边说”的实时全双工一度被当成离散 AR 的专属领地,这个垄断最近已经被连续路线打破:Thinking Machines 的 TML-Interaction-Small(2026)74用 dMel 输入 + flow head 输出、200ms 微回合交错地边听边说,是一个完全连续、没有任何离散 token 的全双工系统。所以更准确的说法不是”离散更成熟”,而是离散起步早、工程债还得连续路线慢慢补——而这个差距正在被很快抹平。
这里要补一个我们自己的判断,因为它解释了为什么最近越来越多的工作转向连续特征做生成建模(连续自回归),而不是离散 token——这个转向常被读成”连续终于赢了”,但我认为更准确的解释是:领域当前在玩的游戏变了,而这个新游戏恰好对离散不利。
把话说透。离散 token 真正的杀手锏从来不是它今天展示出来的那些,而是一件还没真正发生的事——像文本那样,在海量 audio-only 数据上做自监督预训练。”audio as language” 这个比喻如果要兑现,靠的就是这个:next-token 预训练、scaling law、涌现能力,整套文本 LLM 的红利复制到音频。可现实是,今天几乎没有人在文本那个量级上做纯音频预训练。领域真正的重心是另一件事——audio 和 text 的对齐:要么为了理解任务(ASR、音频问答、audio-LLM),要么为了多模态/实时对话。重心在 alignment,不在 audio-only pre-training。
一旦看清这一点,前面那个”理解端连续领先”的经验事实就有了结构性的解释,而不只是”连续特征信息更丰富”这么浅:在 alignment 这个游戏里,离散化是纯粹的损失,而它的补偿优势(预训练规模)根本没被激活。 你把音频压成离散 token,丢掉的恰恰是对齐和理解最需要的细粒度信息;与此同时,本该用来抵消这个损失的”文本式大规模预训练”又没人做。损失全摊开、红利全闲置——连续特征在这个局里占优,是顺理成章的。
这两件事各有一个信息论定理兜底,不只是直觉。”离散化是纯损失”对应数据处理不等式:任何确定性处理都不增加信息,\(I(X;\,\mathrm{quant}(Z)) \le I(X;Z)\)——量化只会丢,不会补。而”纯重建 latent 对理解 / 对齐不友好”对应信息瓶颈(Tishby 等):对下游任务 Y 最优的表征,是在保住 \(I(Z;Y)\) 的前提下最小化 \(I(X;Z)\) 的那个最小充分统计量;可重建目标要的恰恰相反——最大化 \(I(X;Z)\)(留住一切才能还原波形)。一个在最小化、一个在最大化,方向就拧着。所以”重建最优的 latent 不是下游最优的 latent”不是经验观察,是这两个目标在信息论上根本不指向同一个点。
所以连续路线眼下的涨势,与其说是它本质上更强,不如说是领域的目标函数恰好踩在离散的短板上、躲开了离散的长板。这个判断有一个不太舒服的推论:如果哪天纯音频大规模预训练真的成了主线(算力、数据、动机都到位),离散那张闲置的王牌可能会重新激活,局势又会翻一次。换句话说,discrete vs continuous 谁占优,本质上取决于领域在优化什么——而这件事是会变的。
如果理解归连续、生成归离散这个分工可以永远维持,倒也相安无事——各过各的。但音频偏偏有一个绕不开的需求在逼两边合流:4o-style 实时对话要求一个模型同时听和说。listening 和 speaking 在物理时间上是耦合的——一边听一边说、几百毫秒的延迟预算、双向并行。视觉领域也在做理解+生成统一(Chameleon、Janus、Show-o、Emu3),但驱动力强度不同:视觉的统一是多模态工程的 nice-to-have,理解和生成在产品里通常异步(上传图、问问题、生成图,串行就行);音频的统一是产品物理约束的 must-have——Chameleon 不需要在 200ms 内边看边画,4o 必须在 200ms 内边听边说。
所以问题不是”统一会不会发生”,而是:统一的接口会长什么样? 我看到两条都有真实机会的路线。
路线一:更深、更结构化的 RVQ codec——让离散 token 同时承担理解和生成。
为什么有机会,三个论据。
第一,信息容量其实够。先看一组粗算:连续 WavLM 是 1024 维 float(≈ 32 kbits/frame 的存储位宽——不等于有效信息量,神经特征大量冗余,但数量级感受可用);今天的离散方案——Discrete WavLM 单码本 k-means 约 10 bits/frame,Mimi 8 层 RVQ ≈ 88 bits/frame——分别是 3000× 和 400× 的位宽压缩。在这种容量配置下输给连续,输得并不冤。而理解任务真正需要多少信息?speech understanding 并不需要 waveform 的所有 sample 细节——80 维 log-mel 长期是 ASR / HuBERT / WavLM / Whisper 的标准输入,经典 ASR 用 13–40 维 MFCC 也能跑。输入端只需要每帧几 kbits 量级就足够”听懂”。那么 64 层 RVQ × 10 bits = 640 bits/frame,和 mel 的有效信息量在同一个量级——信息总量不是瓶颈。今天没人做”64 层 RVQ + 能消费多 codebook 流的理解下游”这个实验,是因为 RVQ codec 一直为生成服务(层数越多越伤 AR 展开),不是因为它在原理上不行。“RVQ 在理解上输给连续”目前是个经验事实,不是机制结论。
第二,层级结构天然适配双任务分工。理解任务读前几层(语义层),生成任务用全部层(语义+声学)——RVQ 的层级让同一个 token 流可以按需消费。这个性质单码本没有、连续特征也没有,是 RVQ 独有的结构红利。
第三,当前差距更像 paradigm artifact 而不是 fundamental limit。视觉里早期的 VQGAN 多 codebook 也一度被认为”建模性能差”,直到下游消费方式被重新设计才翻盘。音频还没人认真做这次重新设计。
但路线一有一个关键前提,也是最容易被忽略的陷阱:加深层数远不够,必须配结构性监督。如果只用纯重建 loss 训 64 层 RVQ,可以得到重建极好的 codec——然后很容易以为”这些 token 完美表示了音频”。但 token 里存的不是”音频的原始信息”,而是”让 decoder 还原音频所需的信息”——这两件事不一样。decoder 是有结构、有 inductive bias 的网络,能从先验里补出大量东西(卷积 locality、周期性激活等),所以 token 只需要承载”先验补不出”的那部分——一种更熵密、更纠缠的形式。对下游 LLM 来说,这种纯重建 token 可能比直接喂 mel 还难读——LLM 没有 codec decoder 的那些先验,它面对的是一串”decoder 的私人语言”。这就是为什么 2.3 节那四条路径(distillation / hybrid encoder / supervised / disentanglement)会不约而同地出现——它们都在做同一件事:让 token 的结构对下游 LM 友好,而不仅仅对 decoder 友好。纯重建训出来的 token 是”decoder 的私人语言”,加结构性监督才能变成”LLM 也能读的公共语言”。
所以路线一的完整配方是三件事的联合设计:足够深的层级 + 结构性 token 监督 + 能消费多 codebook 流的下游模型。缺一不可,而且今天没有人把三件事同时做齐。
路线二:轻量、低维、为建模而设计的连续特征——绕过离散化,直接做统一接口。 这条路 §3 已经讲透,这里不重复展开,只收束成判断。理解端,连续本就是现任冠军,一个角白送;生成端,连续 AR + flow head(§3.4)正在快速成熟——VibeVoice75、DiTAR 把单向质量做了上去,TML-Interaction 甚至做出了全双工。而做统一接口的关键前提——“连续特征必须为可建模性专门设计”——正是 §3.3 那套工具箱、§3.2 的语义锚定、§3.5 的维度三角在回答的同一个问题。DashengTokenizer76、WavCube / LoSATok、MingTok 已经给出“既能理解又能生成”的连续 latent 雏形,路线二不再是设想。所以它的完整配方也是三件事的联合设计:语义锚定的低维 latent + 成熟的连续 AR 骨架 + 经得起流式的分布头——前两件已有雏形,最后一件(高维 latent 的流式稳定性,§3.5)还没被验证,这是路线二剩下的唯一硬骨头。
两条路线表面上是离散 vs 连续之争,但它们对表征设计提的要求其实是同一个:表征必须为下游建模而设计——而不是只为重建(codec 的传统目标)或只为识别(SSL 的传统目标)。路线一的”结构性监督”和路线二的”可建模性设计”是同一个需求在两种形态下的表达。这是把 Sander 那个 modelability 维度推到极限的版本:表征设计的目标函数里,下游模型的消费方式从 afterthought 变成 first-class citizen。
我自己的判断:短期内,路线二的混合形态(CosyVoice / Seed-TTS 那种”单层 semantic VQ + flow matching”)已经在产品里跑通,有先发优势;中期两条路线会并行演化,谁先做出”理解生成双优”的完整系统,谁定义下一代标准。至于 RVQ 的层级本身——无论哪条路线胜出,我认为”层级化/结构化的表征”这个性质都不会消失:FACodec 的显式 factorize、SNAC 的 multi-scale、甚至路线二那个假想的”为建模设计的连续 latent”,都是层级思想的不同化身。
4.3 音频的”网格暴政”比视觉更严重
Sander 在原文里讲的一个重要观察是 tyranny of the grid——视觉 latent 平等对待每个空间位置,浪费容量。一张图里背景的大片纹理和前景的关键细节占用同样多的 token,这显然不是最优的信息分配。
这件事在音频上更严重,但讨论得更少。
音频的冗余比图像更不均匀。
- 语音里有大量静音、停顿、辅音持续段、元音稳定段——这些位置的信息量远低于辅音爆破点、元音起始、韵律变化等关键瞬间。
- 音乐里有 intro/outro、单一织体段、长拍——同样信息密度极不均匀。
- 但今天所有主流 codec(EnCodec、DAC、Mimi、SoundStream)都是恒定帧率(50 / 75 / 12.5 Hz),不管说话还是静音都产生同样多的 token。这是网格暴政在音频上的核心症状。
为什么”恒定帧率”在原理上就吃亏,率失真理论说得很干脆:给信源编码,最优策略是让局部码率匹配局部熵率——信息多的地方多给 bit、信息少的地方少给。而语音是个高度非平稳的源,静音段的瞬时熵率接近 0、爆破音和元音起始那一瞬间陡高。用恒定帧率去编它,等于在静音上拿高码率烧钱、又在高熵瞬间供不上 bit——在率失真曲线上这是一个一眼可见的次优点。所以变长 / 内容自适应 tokenization 之所以”应该”赢,不是工程花活,是它在把码率往熵率上对齐、逼近率失真最优——这正是熵编码(算术编码那一类)讲了几十年的老道理,只是这次搬到了 neural codec 的帧率上。
视觉领域已经在反抗。 过去两年视觉 tokenization 出现了一批 content-adaptive 的工作:
- TiTok(Yu et al., 2024)77——用 transformer 把图像压成可变数量的 token(32 或 64),证明固定 grid 不是必需的。
- FlexTok(Bachmann et al., 2025)78——latent token 数量在 inference 时按内容动态调整。
- ElasticTok、CAT: Content-Adaptive Image Tokenization、TokenSet 等——从不同角度攻击固定 grid 假设。
音频领域的对应工作开始出现,但相比视觉社区的规模差距仍然很大。能拿出来对照的:
- Sander 自己 2021 年的 Variable-rate discrete representation learning79——一篇早期但长期孤独的工作。
- SoundStream 的 quantizer dropout——只是”软变长”(同一个模型在不同 bitrate 工作),不是真正的内容自适应。
- SNAC 的 MSRVQ——不同 RVQ 层不同帧率,但每层内部仍然恒定。
- ALMTokenizer(Yang et al., ICML 2025)45——用 query-based quantization 实现 low-bitrate semantic-rich codec,是 TiTok 那条 query-based 路线在音频上的对应物:用 learnable queries 替代固定 1D 时间网格,让 token 数量和内容关联。
- TADA(Dang et al., Hume AI, 2026)80——更激进的做法:把 audio token 通过 CTC + Viterbi forced alignment 1-to-1 对齐到 LLM 的 text token。这样 audio token 的产生不再按”每 X 毫秒一个”,而是按”每个 text token 一个”——快语速产生更多 token、慢语速/静音产生更少。结果是 2-3 FPS 的内容自适应帧率,比 Mimi 的 12.5 Hz 又低了一个量级。这是目前最极端的变长 audio codec。
- FlexiCodec(Li et al., ICLR 2026)81——直接在 codec 里做动态帧率:用冻结的 ASR 特征当”语义尺子”,把帧间余弦相似度高于阈值的相邻帧合并成一帧——信息稀疏处(静音、稳态元音)合并得多、密集处保留更多,阈值推理时可调,平均帧率落在 3–12.5 Hz。合并那一步同样走 query-based 策略45:每段塞一个 query token 去总结段内原始帧,区别只在 query 数量是按相似度动态决定的。它的可贵之处是不靠 text 锚点——纯靠帧间语义相似度,所以原则上对音乐、通用音频也成立,这正是 TADA 那条 text-aligned 路线够不到的地方。但边界也清楚:用的是全序列 ASR 特征、offline 设计,不解决 streaming;而且解码前会用一个 frame-unmerging 模块把变长序列重新展开回 12.5 Hz 定长再喂下游——codec 内部动态,对外仍是定长流,”让下游直接消费动态率 token”被论文列为 future work。
- SAME(Parker et al., Stability AI, 2026)68——把同一套 query-based 压缩搬到了连续侧:它是个面向音乐 / 通用音频的连续 autoencoder(44.1kHz 立体声、4096× 压缩、d=256,瓶颈是 soft-normalisation 而非严格 VAE),重采样靠一个 Transformer Resampling Block——每段后面追加一个 learnable query embedding,过 transformer 让它 attend 段内原始帧,再抽出来当压缩结果。这和 ALMTokenizer 是同一个内核,只是 ALMTokenizer 走离散 + 可变率、SAME 走连续 + 固定 stride。所以严格说 SAME 自己没有反抗网格暴政——它的 query 数量是定长切出来的、帧率恒定;它的意义在于说明 query-based 压缩已经不再是离散 codec 的专利,连续音乐 autoencoder 也在用。把 SAME 这类连续 autoencoder 的固定 stride 换成 FlexiCodec 那种内容自适应的合并,是一个明摆着但还没人走的下一步。
- 一些 streaming codec 探索 VAD-based skip 或 silence-aware down-sampling,但没有 mainstream 方案。
即便加上这几个工作,音频社区对变长 tokenization 的探索仍然落后于视觉——视觉端 TiTok / FlexTok / ElasticTok / CAT / TokenSet 这批工作已经形成一个有体量的研究方向,音频端 ALMTokenizer、TADA、FlexiCodec 这种探索还相对零散、没有形成相互对话的子领域。
关于 streaming + variable-rate 的”冲突”,需要修正一下我一开始的判断:这两件事不是完全不可调和的。TADA 给出了一个有意思的解法——用 text-token 时钟代替 audio-time 时钟。Audio token 不再按物理时间均匀产生,而是和 text token 一起以同步节奏向前推进;既是 streaming(每次产生一对 text+audio token),又是 variable-rate(相同 text token 数可以对应不同长度的 audio)。这是一个聪明的设计——把”变长”的负担转移到 text 这一端,让 audio 端依然保持节奏稳定。
这几个工作各自啃下了难点的一部分:TADA 证明”有 text 锚点时,变长和 streaming 可以兼得”(用 text-token 时钟代替 audio-time 时钟,每次产生一对 text+audio token,既流式又变长);FlexiCodec 证明”不靠 text,也能靠帧间语义相似度做出内容自适应帧率”——把 TADA 够不到的音乐 / 通用音频也覆盖了。
所以这个 Hot Take 的完整版是这样: 音频的网格暴政比视觉更严重(信号本身的冗余分布更不均匀),但好消息是,反抗它的几块拼图最近一两年陆续出现了。真正还没拼齐的是把三件事同时做到:无 text 锚点、内容自适应、且 causal streaming——FlexiCodec 拿下了前两件,但它是 offline 的、不流式,TADA 流式但要靠 text。更深一层的难点还在下游:让一个 LM 原生地消费”每秒 token 数随内容浮动”的变长流(而不是先 padding 或 unmerge 成定长),这件事几乎没人碰——连最前沿的 FlexiCodec 也是在 codec 内部动态、解码前又 unmerge 回定长把下游绕过去,它自己都把”下游直接吃变长流”留作 future work。视觉社区有 TiTok / FlexTok 这批明星工作把变长 tokenization 推成了主流议题,音频这边才刚起步——谁先把”通用音频 + streaming + 内容自适应 + 下游可消费”四件事凑齐,谁就会在下一代音频 LM 的基础设施上占一个关键位置。
4.4 把 Sander 的三角扩展成四面体
Sander 原文最有影响的概念之一是 rate-distortion-modelability 三角——任何 latent 设计都在这三个维度之间做 trade-off:
- Rate:latent 占用多少 bit。压得越狠,下游建模负担越小。
- Distortion:从 latent 重建回信号失真多少。失真越小,质量越高。
- Modelability:latent 对下游生成模型友不友好。结构性越强、可建模性越好。
音频上有几个特殊性让这个三角需要调整:
1. Distortion 维度比视觉更难量化——没有 LPIPS 这种公认的可微感知 loss,所有 distortion 度量(PESQ、UTMOS、VISQOL)都有偏置。这件事 §1.1 讲过。实际意义是:codec 设计者在 distortion 这一维上是“盲调”的,只能靠 multi-discriminator 这种间接近似。这放大了 §2.1 讲的”哲学分歧”——EnCodec 和 DAC 在同一个 “distortion” 名义下其实在优化不同的东西。
2. Modelability 维度和”序列长度”强耦合——音频的 latent 序列即便压到 12.5 Hz,30 秒音频也有数百到上千 token。这对 attention 是个挑战,对 streaming 也是。所以”modelability”在音频里不只是”token 之间是否结构良好”,还隐含”token 流是否够短到能被 LM 高效处理”。
3. 需要加一个新维度——Streaming / latency。Streaming 不是音频独有(视频流、机器人交互、视频生成里也有),但音频的实时对话把它从工程偏好变成了产品硬约束——必须在几百毫秒内边听边说,这是视觉应用很少面对的延迟级别。Streaming 维度直接塑造表征设计的多个细节:
- Causal 卷积 vs non-causal——决定 codec 是否能 streaming。
- AR vs non-AR 建模——决定下游能否 streaming。
- Variable-rate vs fixed-rate——streaming 兼容性截然不同。
所以 Sander 的三角在音频上应该扩展成一个四面体——加上 streaming 这个视觉里不存在、被产品形态强行塞进来的第四维。
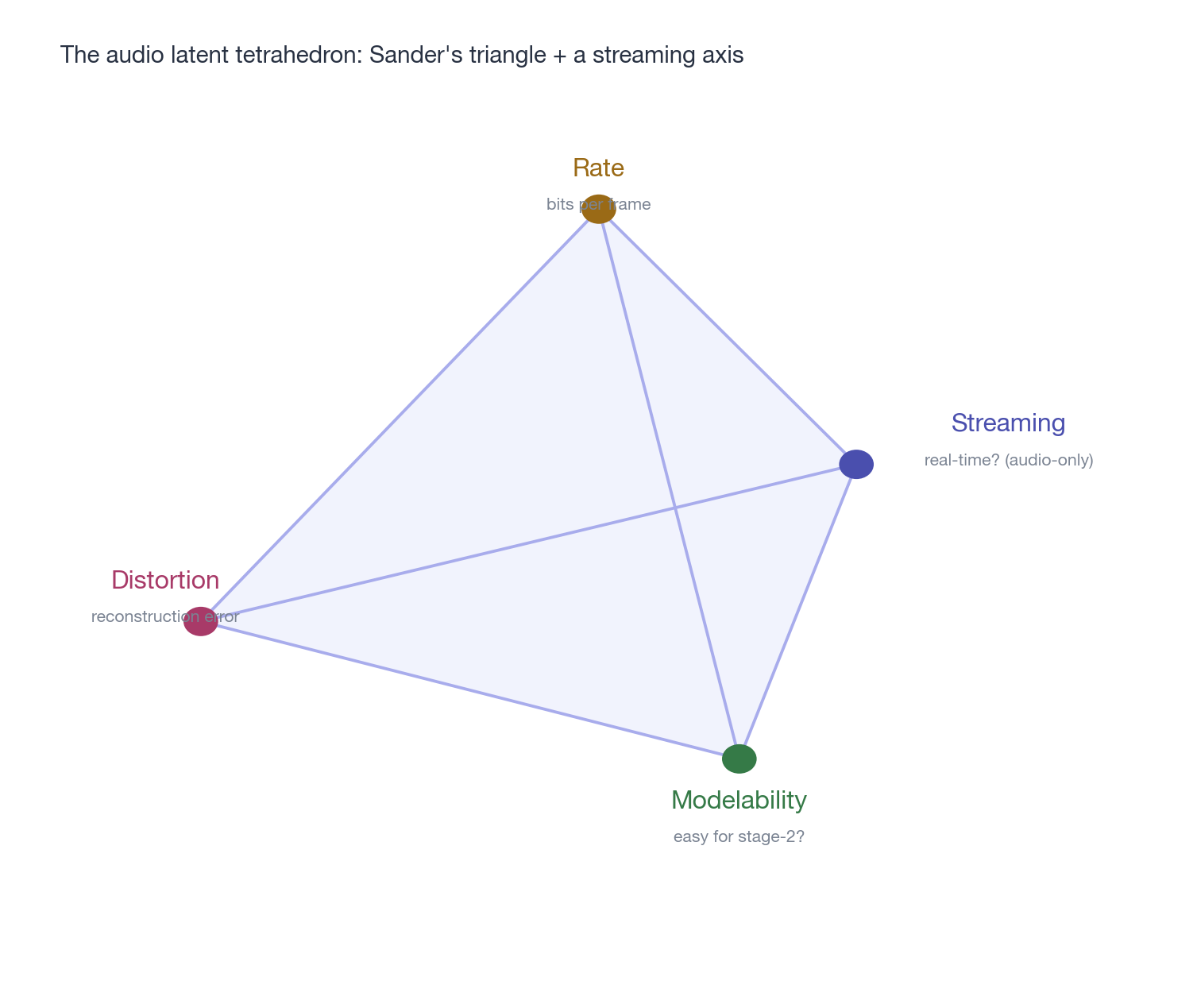
caption:”Rate、Distortion、Modelability 是 Sander 的原三角,Streaming 是音频独有的第四维。任何音频 latent 设计都是这个四面体内部的一个取舍点——而引子里那两个’真正的争议’,其实就是四面体的两条棱:序列长度 vs 每帧容量是 Rate–Modelability 棱,streaming vs offline 是 Streaming–Distortion 棱。”
四面体讲完,引子开头那两个”真正的争议”就各自归了位:序列长度 vs 每帧容量是 Rate–Modelability 之争(Mimi 低帧率高容量 vs WavTokenizer 高帧率单码本,没有谁碾压谁);streaming vs offline是 Streaming–Distortion 之争(离散 AR 流式友好但每帧容量受限,连续 NAR 质量高但流式难)。两个争议都不是”连续 vs 离散”,而是四面体里选哪个角的问题。
但还有一件事落在四面体之外——它问的不是”表征自身好不好建模”,而是”表征好不好嫁接到已有的 text LLM 上”:谁能更轻松地和预训练文本 LLM 一起训? 多模态时代这可能是最现实的胜负手,因为一个表征再优雅,不能复用文本 LLM 的权重和训练基础设施,落地成本就高一个量级。这一维上没有简单赢家:离散的接口天然兼容(扩 vocabulary、复用 embedding、cross-entropy 不变),但兼容不等于高效——音频和文本 token 的粒度差异大、码本几何和文本 embedding 不对齐(LLM-Codec 初始化码本正是在硬修这个);连续这边 loss 异构(flow head 不是 softmax,混合训练的配比和梯度平衡是真问题),但语义锚定的那批连续 latent 反而可能和 LLM 语义空间更天然对齐——毕竟它们本就从理解模型的特征里长出来。
把四面体和这条体系外的轴合起来,全文的判断就一句话:真正决定音频生成未来的,不是”连续还是离散”,而是在这几个底层维度上怎么取舍。 两条路线会继续向中间靠拢、互相借鉴,最终大概率融合成一种”看不出是哪条路出身”的混合表征——而塑造未来十年基础设施形态的,是这些取舍本身。
5. 收尾:开放问题
把一个领域的 latent 设计史讲完,留给未来的是一系列没有定论的问题。这一节列四个我认为接下来 1-3 年值得关注的方向——最后一个会动摇这整篇文章的前提。
音频会收敛到一个统一 latent 吗?
视觉走到过这样一个”收敛时刻”,值得先看清它到底是什么、别把功劳记错。收敛不是 2021 年 VQGAN 发布那一刻发生的,而是 2022 年 Stable Diffusion 把 latent diffusion 模板推成事实标准的时候——而且有意思的是,统一的载体不是 VQGAN 的离散 token(DALL-E 1 / Parti / MUSE 那条离散 AR 路线反而没成为主流),而是”按 VQGAN 配方训练、但去掉量化”的连续 KL-VAE。VQGAN 真正留给后世的不是那个 codebook,而是它的训练配方:重建 loss + LPIPS + patch 对抗——这套配方搬进 SD 的 VAE,成为之后几乎所有图像/视频生成模型的 latent 底座。所以视觉那次”收敛时刻”的准确含义是:某个 learned latent 的训练配方 + 一个杀手级下游应用,让整个领域在一两年内收敛到同一个 latent 模板上。
音频会有这一刻吗?
短期我不太相信——离散和连续两条路(§2、§3)都还在快速演化,每条路内部又有多个子流派(compression-school、semantic-school、disentanglement-school、single-codebook-school 等),任何一种都还没出现”训练配方被全领域复用 + 杀手级应用拉动收敛”的组合。EnCodec、DAC、Mimi 都有成为模板的潜质,但每一个都有明显的设计哲学倾向,离”通用 latent”都还差一步。
中期可能出现的不是单一 codec,而是某种API 兼容的标准化接口——输入波形、输出 multi-codebook RVQ stream、第一层 phonetic-aligned。这样下游 LM / diffusion 不需要关心具体哪个 codec。这种”接口标准化”在视觉里发生过(SDXL 之后 VAE-KL 8× 成为事实标准),音频里有理由相信类似事件会发生——至于这个接口更可能是更深的 RVQ 还是更轻的连续特征,§4.2 已经掰过两条路线的胜算。
End-to-end 在音频上比视觉更难
视觉社区从 VAE → VQGAN → latent diffusion 这一路走得很顺,每一代都是某种 end-to-end 的清晰演化。音频上 end-to-end 一直没有真正胜出——TTS 至今仍然是 text → semantic token → acoustic feature → vocoder 这种多阶段拼接。原因 §1 讲过:相位悖论 + 缺乏可微感知 loss + 长序列约束,让”一个模型从头到尾”在工程上特别难。
这件事的具体表现是 neural codec 出现五年了,但 codec 几乎从不被端到端联训进下游生成模型——VALL-E、Moshi、CosyVoice 都是 codec 先训好 freeze,再训上面的 LM。这和视觉里 SDXL “latent VAE 和 diffusion 联训” 的实践不同。如果未来几年有人把 audio codec + 下游真正联训跑起来,离散和连续的二分会进一步模糊;如果跑不起来,两阶段范式会作为音频领域的”路径依赖现实”长期存在。
多模态时代音频 latent 的位置
GPT-4o 这种”统一架构”出现之后,音频不再是一个独立研究域——它必须和 text / image / video 共享一个 transformer backbone。这对音频 latent 设计提出了新的硬约束:
- 音频 latent 会被推向 token-like interface——跨模态时 transformer backbone 需要能高效消费它。这可以是显式离散 token,也可以是低帧率 continuous embeddings 经过 projector / resampler 接入;离散化是最直接复用 LLM next-token 训练、KV cache 和 in-context learning 的方案,但不是唯一选择。
- 音频 token 的”语速”必须和 text / image token 的语速协调——TADA 那种 text-aligned tokenization 正是直接回应这件事的。
- 跨模态的 in-context learning 要求音频 token 携带结构性强的信息,而不是 decoder 的私人语言——也就是前面反复讲的”结构性 token 监督”。
所以多模态时代不只是把音频塞进多模态 transformer 那么简单——它会反过来重塑音频 latent 设计的优先级。不是音频按自己的节奏演化、最后被多模态吸纳,而是多模态的需求反推音频 latent 朝特定方向加速演化。
Audio encoder / codec 会不会干脆消失?
最后这个问题动摇的是整篇文章的前提。这篇博客从头到尾假设音频生成需要一个 latent 中间层——但最近两个方向在试探”能不能不要”:理解端,Gemma 4 这类多模态模型直接把音频喂进 LLM;生成端,一批工作(WaveTTS 之类)回到直接建模 waveform。如果这两条都成立,那 audio encoder 和 codec 是不是终将多余?
理解端最激进的一步是连 encoder 都不要了。Gemma 4 的官方说法82是”把 audio encoder 整个去掉,直接把原始音频信号投影到和 text token 相同的维度空间”(和它的 vision 路线一致,两个模态都 encoder-free)。没有预训练 encoder、没有中间特征,raw audio 经一个投影层就变成 token embedding,剩下全交给共享的 transformer backbone。
这看上去像”encoder 彻底消失了”,但更准确的说法是 encoding 这个功能没消失,只是从一个独立可复用的模块,被彻底分散进了共享 backbone。两个细节能看出它没真的消失:其一,把高熵波形压成低熵语义这件事还得有人做,现在是 backbone 的某些层在隐式做(那个 mel 80 维论证仍然成立——听懂不需要 sample 细节);其二也更硬——raw audio 一秒两万多个采样点,不可能一秒两万个 token,所以那个”投影层”必然把一块采样映射成一个 token,这个”块→token”本身就是降帧率,只是换了个不起眼的地方做掉了。encoder 这个名字没了,但 encoder 干的两件事——抽象和降率——一件都没省。
这其实是 bitter lesson 在理解端的预演:与其手工设计一个 encoder,不如让足够大的模型 + 足够多的算力自己学会编码。所以理解端真正的趋势不是”encoder 存不存在”,而是”编码这件事要不要做成一个独立模块”——独立模块的价值在于可复用、可跨任务迁移、可单独优化,而端到端吸收的价值在于不被人手设计的归纳偏置卡住、让 scaling 自己说话。
生成端”直接建模 waveform”是同一个 bitter lesson 的另一面——而且它不是新事。 WaveNet(2016)、波形扩散(WaveGrad / DiffWave,2020)都试过端到端 waveform 生成,§3.1 讲过它们为什么败给 latent:波形太长、采样太慢。现在它卷土重来(WaveTTS 之类),靠的不是想法新,是算力和架构效率——更省的 attention、更好的并行,让”直接吞几万个采样点”从不可行变成勉强可行。所以两端其实是同一个问题:当算力足够,”为了让下游好建模而做的有损压缩 / 显式编码”这个动机会不会逐渐失效,让模型越来越贴近原始信号?
我的判断是:编码这个功能不会消失,但可能不再是独立模块;而 streaming 会拖住整个趋势。 短期纯压缩型 codec(为传输设计的那种)确实可能让位——算力够了,压缩率不再是硬约束,理解端的独立 encoder 也可能像 Gemma 那样被吸收进大模型。但”把信号整理成好建模形态”这个职能不会因算力增长而消失,反而因模型变大、上下文变长而更重要。更关键的是音频那个视觉没有的硬约束:边听边说要求紧凑表征。一个实时对话系统不可能每帧吞吐几万个采样点——延迟和算力都不允许。只要 streaming 是音频的核心产品形态,把信号压成低帧率表征这件事就有不可替代的理由——不管这个压缩是由独立 codec 做的,还是被模型内部某几层悄悄做掉的。
放回四面体看,这正是一组动态张力:bitter lesson 在不断削弱 Rate 维的重要性(算力够了就不在乎压多狠),但 Streaming 维死死顶住它(实时永远要紧凑)。所以最可能的未来不是”latent 消失”,而是离线高质量生成越来越敢贴近原始信号、实时交互生成继续依赖紧凑 latent——这条线和前面”离散管 streaming、连续管质量”的分工,其实是同一条裂缝在不同维度上的投影。
致谢
特别感谢 Sander Dieleman 的原文 Generative modelling in latent space——它给了这篇文章整个 framing,这篇博客在某种意义上算是它的”音频版续集”。
这个领域过去五年的进展,来自整个 audio codec / audio LM 社区。受篇幅所限,我没办法把每一篇相关工作都引进来,挂一漏万在所难免——但这篇文章本质上是站在所有这些工作之上的一次梳理,在此一并向每一篇推动了这个领域的论文致谢。
文中的判断和那些 Hot Take 都只代表我个人此刻的看法,难免有不成熟、甚至看错的地方。非常欢迎你来找我讨论、提问,或者直接指出哪里写错了——X(推特)@dcyang98、邮箱 dcyang@se.cuhk.edu.hk,或 GitHub @yangdongchao。
参考文献
-
Sander Dieleman, “Generative modelling in latent space”, blog 2025. https://sander.ai/2025/04/15/latents.html ↩
-
McDermott & Simoncelli, “Sound Texture Perception via Statistics of the Auditory Periphery”, Neuron 2011. https://doi.org/10.1016/j.neuron.2011.06.032 ↩
-
Kong et al., “HiFi-GAN: GANs for Efficient and High Fidelity Speech Synthesis”, NeurIPS 2020. https://arxiv.org/abs/2010.05646 ↩
-
Stevens, Volkmann & Newman, “A Scale for the Measurement of the Psychological Magnitude Pitch” (the mel scale), J. Acoust. Soc. Am. 1937. https://doi.org/10.1121/1.1915893 ↩
-
Davis & Mermelstein, “Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences” (MFCC), IEEE TASSP 1980. https://doi.org/10.1109/TASSP.1980.1163420 ↩
-
Shen et al., “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions” (Tacotron 2), ICASSP 2018. https://arxiv.org/abs/1712.05884 ↩
-
Esser et al., “Taming Transformers for High-Resolution Image Synthesis” (VQGAN), CVPR 2021. https://arxiv.org/abs/2012.09841 ↩
-
van den Oord et al., “Neural Discrete Representation Learning” (VQ-VAE), NeurIPS 2017. https://arxiv.org/abs/1711.00937 ↩
-
Dhariwal et al., “Jukebox: A Generative Model for Music”, 2020. https://arxiv.org/abs/2005.00341 ↩
-
Zeghidour et al., “SoundStream: An End-to-End Neural Audio Codec”, IEEE/ACM TASLP 2021. https://arxiv.org/abs/2107.03312 ↩
-
Défossez et al., “High Fidelity Neural Audio Compression” (EnCodec), TMLR 2023. https://arxiv.org/abs/2210.13438 ↩
-
Kumar et al., “High-Fidelity Audio Compression with Improved RVQGAN” (DAC), NeurIPS 2023. https://arxiv.org/abs/2306.06546 ↩
-
Mousavi et al., “DASB — Discrete Audio and Speech Benchmark”, 2024. https://arxiv.org/abs/2406.14294 ↩
-
Mousavi et al., “Discrete Audio Tokens: More Than a Survey!”, TMLR 2025. https://arxiv.org/abs/2506.10274 ↩
-
Borsos et al., “AudioLM: a Language Modeling Approach to Audio Generation”, 2022. https://arxiv.org/abs/2209.03143 ↩
-
Chen et al., “WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing”, 2021. https://arxiv.org/abs/2110.13900 ↩
-
Ji et al., “WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling”, ICLR 2025. https://arxiv.org/abs/2408.16532 ↩
-
Xin et al., “BigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec”, 2024. https://arxiv.org/abs/2409.05377 ↩
-
Wu et al., “TS3-Codec: Transformer-Based Simple Streaming Single Codec”, 2024. https://arxiv.org/abs/2411.18803 ↩
-
Bai et al., “dMel: Speech Tokenization made Simple”, 2024. https://arxiv.org/abs/2407.15835 ↩
-
Siuzdak et al., “SNAC: Multi-Scale Neural Audio Codec”, 2024. https://arxiv.org/abs/2410.14411 ↩
-
Yang et al., “UniAudio 1.5: LLM-driven Audio Codec is A Few-shot Audio Task Learner” (LLM-Codec), NeurIPS 2024. https://arxiv.org/abs/2406.10056 ↩
-
Mentzer et al., “Finite Scalar Quantization: VQ-VAE Made Simple” (FSQ), ICLR 2024. https://arxiv.org/abs/2309.15505 ↩
-
Yang et al., “HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec”, 2023. https://arxiv.org/abs/2305.02765 ↩
-
Gu & Diao, “ESC: Efficient Speech Coding with Cross-Scale Residual Vector Quantized Transformers”, EMNLP 2024. https://arxiv.org/abs/2404.19441 ↩
-
Chiu et al., “Self-supervised Learning with Random-projection Quantizer for Speech Recognition” (BEST-RQ), ICML 2022. https://arxiv.org/abs/2202.01855 ↩
-
Hsu et al., “HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, 2021. https://arxiv.org/abs/2106.07447 ↩
-
Anastassiou et al., “Seed-TTS: A Family of High-Quality Versatile Speech Generation Models”, 2024. https://arxiv.org/abs/2406.02430 ↩
-
Chung et al., “w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training”, ASRU 2021. https://arxiv.org/abs/2108.06209 ↩
-
Zhang et al., “SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models”, ICLR 2024. https://arxiv.org/abs/2308.16692 ↩
-
Défossez et al., “Moshi: a speech-text foundation model for real-time dialogue” (incl. Mimi), 2024. https://arxiv.org/abs/2410.00037 ↩
-
Liu et al., “SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, 2024. https://arxiv.org/abs/2405.00233 ↩
-
Ye et al., “Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model” (X-Codec), AAAI 2025. https://arxiv.org/abs/2408.17175 ↩
-
Du et al., “CosyVoice: A Scalable Multilingual Zero-shot TTS Synthesizer based on Supervised Semantic Tokens”, 2024. https://arxiv.org/abs/2407.05407 ↩
-
Har-Tuv et al., “PAST: Phonetic-Acoustic Speech Tokenizer”, Interspeech 2025. https://arxiv.org/abs/2505.14470 ↩
-
Ju et al., “NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models” (FACodec), ICML 2024. https://arxiv.org/abs/2403.03100 ↩ ↩2
-
Ren et al., “Fewer-token Neural Speech Codec with Time-invariant Codes” (TiCodec), ICASSP 2024. https://arxiv.org/abs/2310.00014 ↩
-
Bie et al., “Learning Source Disentanglement in Neural Audio Codec” (SD-Codec), ICASSP 2025. https://arxiv.org/abs/2409.11228 ↩
-
Wang et al., “Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers” (VALL-E), 2023. https://arxiv.org/abs/2301.02111 ↩
-
Copet et al., “Simple and Controllable Music Generation” (MusicGen), NeurIPS 2023. https://arxiv.org/abs/2306.05284 ↩
-
Ziv et al., “Masked Audio Generation using a Single Non-Autoregressive Transformer” (MAGNeT), ICLR 2024. https://arxiv.org/abs/2401.04577 ↩
-
Yang et al., “UniAudio: An Audio Foundation Model Toward Universal Audio Generation”, ICML 2024. https://arxiv.org/abs/2310.00704 ↩
-
Yang et al., “Diffsound: Discrete Diffusion Model for Text-to-sound Generation”, IEEE/ACM TASLP 2023. https://arxiv.org/abs/2207.09983 ↩
-
Borsos et al., “SoundStorm: Efficient Parallel Audio Generation”, 2023. https://arxiv.org/abs/2305.09636 ↩
-
Yang et al., “ALMTokenizer: A Low-bitrate and Semantic-rich Audio Codec Tokenizer for Audio Language Modeling”, ICML 2025. https://arxiv.org/abs/2504.10344 ↩ ↩2 ↩3
-
Yang et al., “Generative De-Quantization for Neural Speech Codec via Latent Diffusion” (LaDiffCodec), ICASSP 2024. https://arxiv.org/abs/2311.08330 ↩
-
Chung et al., “A Recurrent Latent Variable Model for Sequential Data” (VRNN), NeurIPS 2015. https://arxiv.org/abs/1506.02216 ↩
-
Fraccaro et al., “Sequential Neural Models with Stochastic Layers” (SRNN), NeurIPS 2016. https://arxiv.org/abs/1605.07571 ↩
-
Hsu, Zhang, Glass, “Unsupervised Learning of Disentangled and Interpretable Representations from Sequential Data” (FHVAE), NeurIPS 2017. https://arxiv.org/abs/1709.07902 ↩
-
Toda & Tokuda, “A Speech Parameter Generation Algorithm Considering Global Variance for HMM-Based Speech Synthesis”, IEICE 2007. https://doi.org/10.1093/ietisy/e90-d.5.816 ↩
-
Kim et al., “Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech” (VITS), ICML 2021. https://arxiv.org/abs/2106.06103 ↩
-
Huang et al., “Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models”, ICML 2023. https://arxiv.org/abs/2301.12661 ↩
-
Evans et al., “Stable Audio Open”, 2024. https://arxiv.org/abs/2407.14358 ↩
-
Podell et al., “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”, 2023. https://arxiv.org/abs/2307.01952 ↩
-
Pasini et al., “Music2Latent: Consistency Autoencoders for Latent Audio Compression”, ISMIR 2024. https://arxiv.org/abs/2408.06500 ↩
-
Le et al., “Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale”, NeurIPS 2023. https://arxiv.org/abs/2306.15687 ↩
-
Mehta et al., “Matcha-TTS: A fast TTS architecture with conditional flow matching”, ICASSP 2024. https://arxiv.org/abs/2309.03199 ↩
-
Yang et al., “SimpleSpeech: Towards Simple and Efficient TTS with Scalar Latent Transformer Diffusion Models” (incl. SQ-Codec), Interspeech 2024. https://arxiv.org/abs/2406.02328 · “SimpleSpeech 2”, 2024. https://arxiv.org/abs/2408.13893 ↩
-
Eskimez et al., “E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS”, 2024. https://arxiv.org/abs/2406.18009 ↩
-
Yu et al., “Representation Alignment for Generation” (REPA), ICLR 2025. https://arxiv.org/abs/2410.06940 ↩
-
Zheng et al., “Diffusion Transformers with Representation Autoencoders” (RAE), 2025. https://arxiv.org/abs/2510.11690 ↩
-
Oko, Akiyama, Suzuki, “Diffusion Models are Minimax Optimal Distribution Estimators”, ICML 2023. https://arxiv.org/abs/2303.01861 ↩
-
De Bortoli, “Convergence of Denoising Diffusion Models Under the Manifold Hypothesis”, TMLR 2022. https://arxiv.org/abs/2208.05314 ↩
-
Yan et al. (Inclusion AI), “Ming-UniAudio: Speech LLM for Joint Understanding, Generation and Editing with Unified Representation” (MingTok-Audio 连续 tokenizer), 2025. https://arxiv.org/abs/2511.05516 ↩
-
Yang et al., “WavCube: Unifying Speech Representation for Understanding and Generation via Semantic-Acoustic Joint Modeling”, 2026. https://arxiv.org/abs/2605.06407 ↩
-
Zhang et al., “LoSATok: Low-dimensional Semantic-Acoustic Tokenizer for Cross-Domain Audio Understanding and Generation”, 2026. https://arxiv.org/abs/2605.27840 ↩
-
Kwon, Kim, Ohn, Chae, “Nonparametric estimation of a factorizable density using diffusion models”, 2025. https://arxiv.org/abs/2501.01783 ↩
-
Parker et al., “SAME: A Semantically-Aligned Music Autoencoder”, 2026. https://arxiv.org/abs/2605.18613 ↩ ↩2
-
Chen et al., “F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching”, ACL 2025. https://arxiv.org/abs/2410.06885 ↩
-
Meng et al., “Autoregressive Speech Synthesis without Vector Quantization” (MELLE), ACL 2025. https://arxiv.org/abs/2407.08551 ↩
-
Tschannen et al., “GIVT: Generative Infinite-Vocabulary Transformers”, ECCV 2024. https://arxiv.org/abs/2312.02116 ↩
-
Li et al., “Autoregressive Image Generation without Vector Quantization” (MAR), NeurIPS 2024. https://arxiv.org/abs/2406.11838 ↩
-
Jia et al., “DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation”, ICML 2025. https://arxiv.org/abs/2502.03930 ↩
-
Thinking Machines Lab, “Interaction Models: A Scalable Approach to Human-AI Collaboration” (TML-Interaction-Small;dMel 输入 + flow head,200ms 全双工), 2026. https://thinkingmachines.ai/blog/interaction-models/ ↩
-
“VibeVoice Technical Report”, Microsoft 2025. https://arxiv.org/abs/2508.19205 ↩
-
Dinkel et al., “DashengTokenizer: One layer is enough for unified audio understanding and generation”, 2026. https://arxiv.org/abs/2602.23765 ↩
-
Yu et al., “An Image is Worth 32 Tokens for Reconstruction and Generation” (TiTok), NeurIPS 2024. https://arxiv.org/abs/2406.07550 ↩
-
Bachmann et al., “FlexTok: Resampling Images into 1D Token Sequences of Flexible Length”, ICML 2025. https://arxiv.org/abs/2502.13967 ↩
-
Dieleman et al., “Variable-rate discrete representation learning”, 2021. https://arxiv.org/abs/2103.06089 ↩
-
Dang et al., “TADA: A Generative Framework for Speech Modeling via Text-Acoustic Dual Alignment”, 2026. https://arxiv.org/abs/2602.23068 ↩
-
Li et al., “FlexiCodec: A Dynamic Neural Audio Codec for Low Frame Rates”, ICLR 2026. https://arxiv.org/abs/2510.00981 ↩
-
Google, “Introducing Gemma 4 12B” (encoder-free, raw-audio projection), 2026. https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/ ↩