UniAudio 2.0: A Unified Audio Language Model with Text-Aligned Factorized Audio Tokenization
📦 Code and Checkpoints: 👉 https://github.com/yangdongchao/UniAudio2
📦 Paper: 👉 UniAudio2.0
Introduction
We study two foundational problems in audio language models: (1) how to design an audio tokenizer that can serve as an intermediate representation for both understanding and generation; and (2) how to build an audio foundation model that generalizes in few-shot and zero-shot settings, analogous to large text language models. To this end, we make two contributions. First, we propose ReasoningCodec, a discrete audio codec that factorizes audio into (i) reasoning tokens, which encode text-aligned, high-level analysis and planning representations for audio understanding and hierarchical generation, and (ii) reconstruction tokens, which encode semantic-rich acoustic cues for high-fidelity waveform reconstruction. This design yields understanding performance comparable to strong continuous representations while improving generation quality and reconstruction fidelity over prior discrete tokenizers. Second, we introduce a unified autoregressive architecture for text and audio, together with multi-stage training and multi-task data construction. Using this framework, we train UniAudio 2.0 on 100B text tokens and 60B audio tokens. Across a wide range of speech, sound, and music tasks, UniAudio 2.0 performs competitively on in-domain evaluations and demonstrates strong few-shot and zero-shot generalization to unseen tasks. Demo, Code and checkpoints will be available at \href{https://uniaudio2.github.io/demo/}{https://uniaudio2.github.io/demo/}.
The overview of UniAudio 2.0 as following picture shows.
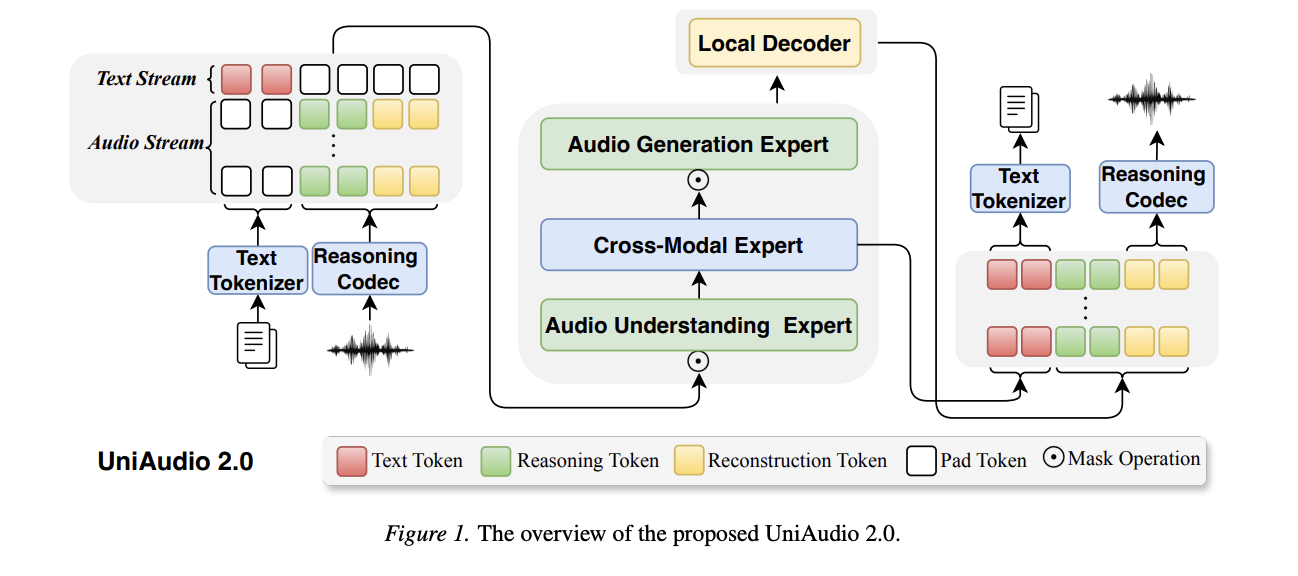
In the following, we give the demo for each tasks.
Audio Codec Tokenizer Reconstruction Comparison
TTS Demo
Text-to-Speech (English)
| he began a confused complaint against the wizard who had vanished behind the curtain on the left | |||
| give not so earnest a mind to these mummeries child | |||
| a golden fortune and a happy life |
Text-to-Speech (Chinese)
| 通过创新技术让未来出行更加安全,高效。 | |||
| 全球每年有超过一百三十五万人,因交通事故而死亡。 | |||
| 拿一只中型平底锅,用中大火融化奶油,加入面粉搅拌至滑顺。 |
Text-to-Speech (Yue / 粤语)
| 以上为转载 | ||
| 人来人往 | ||
| 同色至有得倾 | ||
| 你哋查唔查到呢个字 | ||
| 不如自己谂办法 |
Text-to-Sound Demo
Text-to-sound generation: given a text description (caption), the model generates the corresponding sound. Below are samples from our model (Ours).
| A large crowd cheers and applauds | |
| A race car approaches quickly and slows down squealing tires | |
| A man speaks as a vehicle engine idles |
Text-to-Music Demo
Text-to-music generation: given a text description (caption), the model generates the corresponding music. Below are samples from our model (Ours).
| A male vocalist sings this energetic Punjabi folk song. The tempo is medium fast with an infectious tabla and Dhol percussive beat, ektara rhythm and a funky keyboard accompaniment. The song is lively, spirited, cheerful, simple, happy, playful, enthusiastic, vivacious with a festive, celebratory vibe and dance groove. This song is a Festive Punjabi Folk song. | |
| A male singer sings Arabic vocals with backup singers in vocal harmony. The song is medium tempo with a steady drumming rhythm, percussive bass line, keyboard accompaniment and percussive hits. The song is an Arabic dance song. | |
| This is a classical music waltz piece played on a glass harp instrument. The melody is being played on the smaller glasses at a higher pitch while the rhythm is being played on the bigger glass at a medium pitch. The piece is being played at a cathedral which gives a nice resonance and natural reverb effect. The piece has a unique character. It can be played in the soundtracks of children’s movies/TV shows. |
Song Generation Demo
Song generation: given lyrics (text), the model generates the corresponding singing. Below are samples from our model (Ours).
Song Generation (English)
| Long time ago in Bethlehem, so the Holy Bible says, | |
| One day long time but it’s over now. | |
| The truth is I haven’t got a clue. One thing you know where I’m going. | |
| Buffalo’s happening now, we’re on the move now The bills are happening now, they’re making it happen now We’ve got the spirit, a lot of spirit, yeah | |
| If I tell the world I’ll never say enough Cause it was not said to you And that’s exactly what I want |
Song Generation (Chinese)
| 爱与不爱, 是最痛苦的徘徊, 表面不爱, 但心里仍期待, Hello, 我想你 | |
| 我的眼光闪烁闪烁好空洞, 我的心跳扑通扑通地阵阵悸动. |
InstructTTS Demo
InstructTTS: given an instruction (style/caption) and content (text), the model generates speech that follows the instruction. Below are samples comparing Mimi and Ours.
InstructTTS (English)
| A young adult female, brimming with enthusiasm, expresses her thoughts animatedly, her words punctuated by subtle pauses. Her slightly low-pitch voice carries a melodious tone, resonating with the passion in her words. | Help, oh help.What kind of help?Speak man?What means that?Bloody knifetis hot, it smokes. | ||
| A middle-aged man, his voice rich with emotion and animated expressions. | On november sixteen twenty sixteen, catherine vargas, an executive assistant to kushner, received a request for a meeting with russian ambassador sergey kislyak. |
InstructTTS (Chinese)
| 语气中充满了悲伤痛苦,声音较小传递了悲痛欲绝的情绪 | 能一直选择面对,选择用尽办法来挽救我们的婚姻,我能怪他什么啊。 | ||
| 悲伤逆流成河 | 一年又一年,一日复一日,一聚一离别,一生一场梦。 | ||
| 内心对他人感到抱歉,责怪自己 | 抱歉让你认识一个这么差劲的我。 |
Audio-Instructed TTS (zero-shot)
Given an audio prompt (voice timbre), a caption (style description), and speech content (text), the model generates speech that follows the prompt voice and style. The test data of Chinese TTS come from https://github.com/thuhcsi/SECap
Audio-Instructed TTS (English)
| In early december twenty sixteen dmitriev again broached the topic of meeting incoming administration officials with nader in january or february. | With a moderate pace, a middle-aged woman’s voice carries an air of genuine enthusiasm. Her tone is strikingly expressive and animated. | ||
| The security council, which includes russia, was scheduled to vote on the resolution the following day.There was speculation in the media that the obama administration would not oppose the resolution. | In the midst of her speech, a middle-aged woman moderates her tone, exhibiting a slight yet animated expression. |
Audio-Instructed TTS (Chinese)
| 人生就像剥洋葱,总有一片会让你流泪。 | 伤心难过,声音颤抖,情绪激动失望 | ||
| 心痛?要怪就怪自己,有本事爱上别人,没本事让别人爱上自己。 | 伤心难过,又无能为力 | ||
| 抱歉让你认识一个这么差劲的我。 | 内心对他人感到抱歉,责怪自己 | ||
| 他如果真的爱你,你就不会这么难过了。 | 伤心不已,悲伤凄凉 |
Speech edit
Speech edit: the user asks give a speech and a prompt to modify the speech; the model responds in speech.
| 1 | edit the speech with whisper style | ||
| 2 | edit the speech with shouting style | ||
| 3 | make the speech speaking slow | ||
| 4 | make the speech speaking fast |
Dysarthric Speech Recognition (zero-shot)
Dysarthric speech recognition: given dysarthric (impaired) speech audio, the model recognizes the spoken content. Below are samples with ground truth transcription and our model’s recognition result (Ours).
| Sentence | Sentence | |
| dissatisfaction | dissatisfaction | |
| so | so |
Speech_Sound generation (zero-shot)
Speech-with-sound generation: given speech content (text) and a sound tag, the model generates audio that contains both the speech and the specified sound. Below are samples from our model (Ours).
| but it’s not the first occurrence of its charming kind that i know to have involved a child | gunshot_or_gunfire | |
| it’s in a locked drawer it has not been out for years | cello | |
| somehow of all the days when the home feeling was the strongest this day it seemed as if she could bear it no longer | saxophone | |
| oh she cried coming out of her rapture a little and springing over to mr king with phronsie still in her arms | acoustic_guitar |
Speech-to-Text Question Answer (zero-shot)
Speech-to-text Q&A: the user asks a question in speech; the model responds in text. Below are samples with the question audio and our model’s text answer (Ours).
| 1 | Famous actors like Meryl Streep and Julia Roberts began their careers on Broadway, with Streep winning an Oscar for her performance in The Royal Family. | |
| 2 | The US states got their names from Native American languages, with some names being derived from local tribes or geographical features. |
One-Shot Speech Denoising (few-shot)
One-shot speech denoising: given one demonstration pair (noisy source → clean target), the model denoises a query noisy clip. Below we show the demonstration (source and target), the query noisy audio, ground truth clean (GT), and outputs from Mimi and Ours.
| 1 | ||||||
| 2 | ||||||
| 3 |
One-Shot Voice Conversion (few-shot)
One-shot voice conversion: given one demonstration pair (source voice → target voice), the model converts the query speech to the target voice. Below we show the demonstration (source voice and target voice), the query speech to convert, ground truth (same content in target voice), and outputs from Mimi and Ours.
| 1 | ||||||
| 2 | ||||||
| 3 |
Few-Shot Sound Classification Demo
Few-shot (2-way) sound classification: given two support pairs (source1_audio → text_1, source2_audio → text_2) and a question that defines the two candidate classes, the model classifies the query audio. Below we show Question, Source1 (audio), Text1, Source2 (audio), Text2, Query (audio), Mimo-audio, Ours, and GT.
| 1 | For each of the following input output pairs, output is one of audio scene: [hand_saw or airplane] | airplane | hand_saw | airplane | hand_saw | hand_saw | |||
| 2 | For each of the following input output pairs, output is one of audio scene: [toilet_flush or sneezing] | sneezing | toilet_flush | sneezing | sneezing | sneezing | |||
| 3 | For each of the following input output pairs, output is one of audio scene: [frog or clock_tick] | frog | clock_tick | frog | frog | frog | |||
| 4 | For each of the following input output pairs, output is one of audio scene: [mouse_click or cow] | mouse_click | cow | mouse_click | cow | cow | |||
| 5 | For each of the following input output pairs, output is one of audio scene: [clapping or thunderstorm] | thunderstorm | clapping | thunderstorm | thunderstorm | thunderstorm |
Conclusion
In this study, we investigate how to build a unified audio foundation model that supports both understanding and generation. We propose ReasoningCodec, which factorizes audio into reasoning tokens and reconstruction tokens, and train UniAudio 2.0 with a unified autoregressive architecture and a multi-stage, multi-task training strategy. Experiments show strong performance on seen speech, sound, and music tasks, as well as encouraging few-shot and zero-shot generalization to unseen tasks. Extensive ablation studies suggest that scaling data/task diversity and model size is key to improving generalization on unseen tasks. In the future, we plan to scale both the model and the training data to further improve generalization.
Limitations
In this study, we focus on building a multi-task audio foundation model that supports diverse audio understanding and generation tasks. It can also generalize to many unseen tasks in few-shot or zero-shot settings. However, several limitations remain.
(1) To improve reconstruction quality for sound and music, we adopt a flow-based decoder to recover waveforms from semantic tokens. The multi-step decoding procedure in flow matching increases inference latency for generation. In the future, it is necessary to explore few-step decoding (e.g., two steps) to better balance quality and generation speed.
(2) Although UniAudio 2.0 demonstrates the ability to handle unseen tasks, there is still room for improvement. In addition, it has not yet been shown to solve arbitrary audio-related tasks. We acknowledge that the set of supported unseen tasks is closely related to the training data. For example, the model currently cannot handle speech diarization, likely because we do not include diarization- or duration-related supervision during training.
(3) Due to limited GPU resources, we have not fully explored scaling behaviors (i.e., scaling laws) of UniAudio 2.0. We only conduct experiments on 1B- and 3B-parameter variants. In the future, scaling to 7B and larger models is a promising direction.
(4) Due to the relatively limited amount of sound and music data compared to speech data, UniAudio~2.0 currently performs better on speech-related tasks. In future work, expanding and improving sound and music datasets is expected to further enhance performance in these domains.
(5) This work primarily focuses on pre-training design choices, such as the audio tokenizer and the unified LLM architecture. As a result, we do not extensively investigate post-training strategies (e.g., multi-task SFT and reinforcement learning). We plan to incorporate more post-training techniques to further improve UniAudio 2.0.
(6) We acknowledge that the set of compared models is not exhaustive. This is partly because many related models are not publicly available, and partly because our framework supports a broad spectrum of tasks, which makes comprehensive comparisons challenging. We respect and appreciate all prior work in this area, even if some are not explicitly discussed due to space limitations. We also do not claim that UniAudio~2.0 universally outperforms all existing approaches; instead, different model architectures, different special task design (e.g. special models for TTS, ASR, diffusion-based unified models) also offer complementary strengths.