Scaling Text-to-speech (TTS) to large-scale datasets has been demonstrated as an effective method for improving the diversity and naturalness of synthesized speech. At the high level, previous large-scale TTS models can be categorized into either Auto-regressive (AR) based (\textit{e.g.}, VALL-E) or Non-auto-regressive (NAR) based models (\textit{e.g.}, NaturalSpeech 2/3). Although these works demonstrate good performance, they still have drawbacks. For instance, AR-based models are plagued by unstable generation quality and slow generation speed; meanwhile, some NAR-based models need phoneme-level duration alignment information, thereby increasing the complexity of data pre-processing, model design, and loss design. In this work, we extend our previous publication and implement a simple and efficient NAR TTS framework, termed SimpleSpeech 2. SimpleSpeech 2 effectively combines the advantages of previous AR-based and NAR-based methods, includes (1) simple data preparation; (2) simple model and loss design; (3) stable and high-quality generation performance while fast generation speed.
Compared to our previous publication, we present ({\romannumeral1}) a detailed analysis of the influence of speech tokenizer and noisy label for TTS performance; ({\romannumeral2}) four distinct types of sentence duration predictors; ({\romannumeral3}) a novel flow-based scalar latent transformer diffusion model. With these improvement, we show a significant improvement in generation performance and generation speed compared to our previous work and other state-of-the-art (SOTA) large-scale TTS models. Furthermore, we show that SimpleSpeech 2 can be seamlessly extended to multilingual TTS by training it on multilingual speech datasets.
Overview
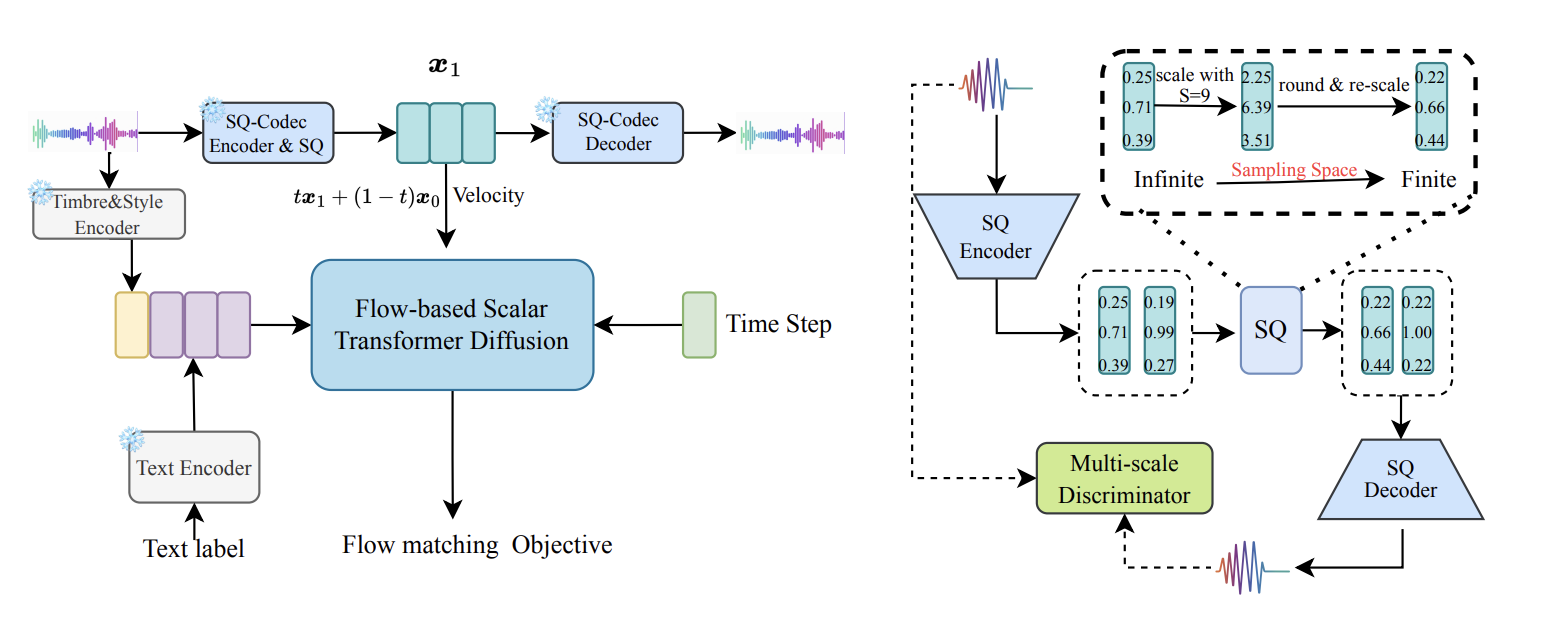
The overview of SimpleSpeech 2 as following picture shows.
In the following, we will show some generated samples by our proposed method.
Zero-shot TTS.
In the following, we first show some case in Common voice, VCTK, RAVDESS, SwitchBoard and LibriTTS test clean set. We compare with VALL-EX, VoiceCraft, NaturalSpeech 2/3, ChatTTS, HierSpeech++, and XTTS
Content (The transcirption of the target audio)
Prompt
GT Speech
VALL-EX
VoiceCraft
NaturalSpeech 2
NaturalSpeech 3
ChatTTS
HierSpeech++
XTTS
Ours
We don’t have the budget to produce it in studio quality.
Large brown dog walks up a blue staircase.
One by one, the campfires were extinguished, and the oasis fell as quiet as the desert.
Thousands of people die every year as a consequence of air pollution
Kids are talking by the door.
Kids are talking by the door.
Kids are talking by the door.
Kids are talking by the door.
when i see her with her friends they do not look like they are all the same age
yeah i like the discount
He is delighted, and he has every right to be
Many complicated ideas about the rainbow have been formed
I don’t suppose any one else can find hidden worms that way
Compared with E3TTS.
Content (The transcirption of the target audio)
Prompt
E3TTS
Ours
You see, sir, these sharks are badly designed.
But the young man was there in presence; and John’s will carried the day.
But at that moment the voice of the stranger was heard from the window.
I don’t suppose any one else can find hidden worms that way.
The ray from his lantern swung about the room for a moment, then he switched on the electric light.
Compared with ARDiT.
Content (The transcirption of the target audio)
Prompt
ARDiT
Ours
It is this that is of interest to theory of knowledge.
For, like as not, they must have thought him a prince when they saw his fine cap.
And lay me down in thy cold bed and leave my shining lot.
Number ten, fresh nelly is waiting on you, good night husband.
He was in deep converse with the clerk and entered the hall holding him by the arm.
Compared with DiTTo-TTS.
Content (The transcirption of the target audio)
Prompt
DiTTo-TTS
Ours
do not therefore think that the gothic school is an easy one.
She felt the force of the objections.
She can’t get it out of her head, even after fifty years.
“I don’t think so,” replied Tom.
But at that moment the voice of the stranger was heard from the window.
Audio Codec Reconstruction comparison
We compared with DAC, HiFi-Codec, Encodec, VAE, and Ours.
Original Speech
DAC
HiFi-Codec
Encodec
VAE
Ours
Ablation study: The influence of Speech tokenizer
In the following, we show the comparison when different speech tokenizer is used, including our SQ-Codec, VAE, and SoundStream. (Corresponding to Table XI in the paper)
Content (The transcirption of the target audio)
Prompt
VAE
SoundStream
SQ-Codec (ours)
But at that moment the voice of the stranger was heard from the window.
“I don’t suppose any one else can find hidden worms that way.”
The ray from his lantern swung about the room for a moment, then he switched on the electric light.
Ablation study: the influence of S and d for SQ-Codec reconstruction
In this part, we show some samples to demonstrate the influence of two parameters (S and d) in SQ-Codec.
S
d
Original Speech
Reconstructed samples
S=10
d=9
S=10
d=9
S=10
d=9
S=20
d=9
S=20
d=9
S=20
d=9
S=50
d=9
S=50
d=9
S=50
d=9
S=32
d=3
S=32
d=3
S=32
d=3
S=32
d=5
S=32
d=5
S=32
d=5
S=32
d=9
S=32
d=9
S=32
d=9
Ablation study: the influence of different SQ-Codec for generation performance
S
d
Content
Generated speech
S=10
d=9
You see, sir, these sharks are badly designed
S=10
d=9
I cannot believe such was the case
S=20
d=9
You see, sir, these sharks are badly designed
S=20
d=9
I cannot believe such was the case
S=32
d=9
You see, sir, these sharks are badly designed
S=32
d=9
I cannot believe such was the case
S=50
d=9
You see, sir, these sharks are badly designed
S=50
d=9
I cannot believe such was the case
S=32
d=3
You see, sir, these sharks are badly designed
S=32
d=3
I cannot believe such was the case
S=32
d=5
You see, sir, these sharks are badly designed
S=32
d=5
I cannot believe such was the case
Ablation study: The influence of different sentence duration for speech synthesis
In this part, we show different sentence duration can be used to synthesize speech, which bring the different prosody.
Content (The transcirption of the target audio)
Setence Duration
Synthesized speech
Kids are talking by the door.
3.5 seconds
Kids are talking by the door.
3 seconds
Kids are talking by the door.
2.5 seconds
Ablation study: DDPM formulation VS Flow-based formulation
Content (The transcirption of the target audio)
DDPM-based
Flow-based
on the at the during this weekend he was there with us.
Many complicated ideas about the rainbow have been formed.
He is delighted, and he has every right to be.
Chinese speech synthesis
We compare with ChatTTS. Note that ChatTTS does not support clone voice.
Content (The transcirption of the target audio)
Prompt
ChatTTS
Ours
抓住互联网浪潮迎来新的发展
他们的资本要求是一样的
一千六百一十七
经济紧张的马某和王某居然想到盗窃汽车卖钱
大发展大繁荣已至窗口期
热带雨林酒店
考虑到目前成交量上涨的情况
音乐搜索给你们
More samples: let chinese voice speak Chinese and Chinglish
 In the following, we will show some generated samples by our proposed method.
In the following, we will show some generated samples by our proposed method.