Diffsound: Discrete Diffusion Model for Text-to-sound Generation
Introduction
This is a demo for our paper Diffsound: Discrete Diffusion Model for Text-to-sound Generation. Code and Pre-trained model can be found on github. In the following, we will show some generated samples by our proposed method. If you want to find more samples, please refer to our github.
Examples
The comprarison between generated sample by AR and Diffsound models and real sound
| Birds and insects make noise during the daytime | |||
| Mel-spectrograms | 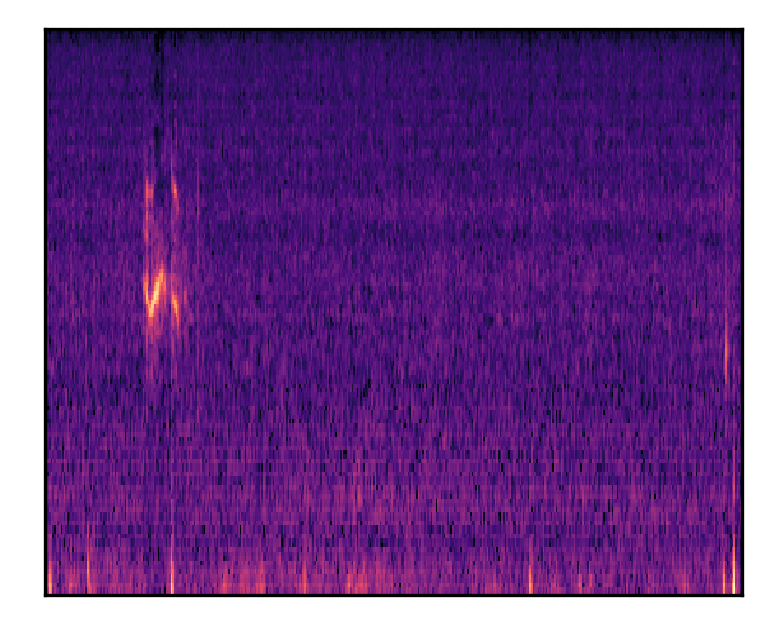 |
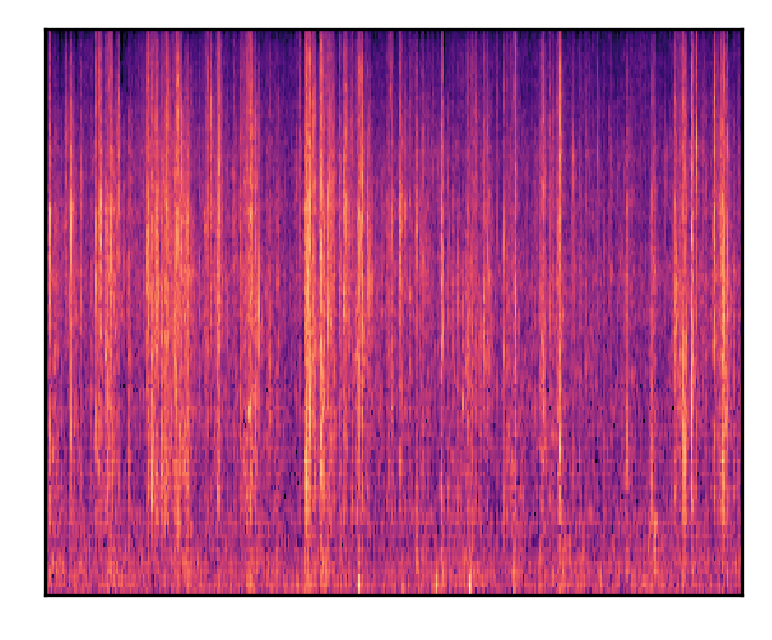 |
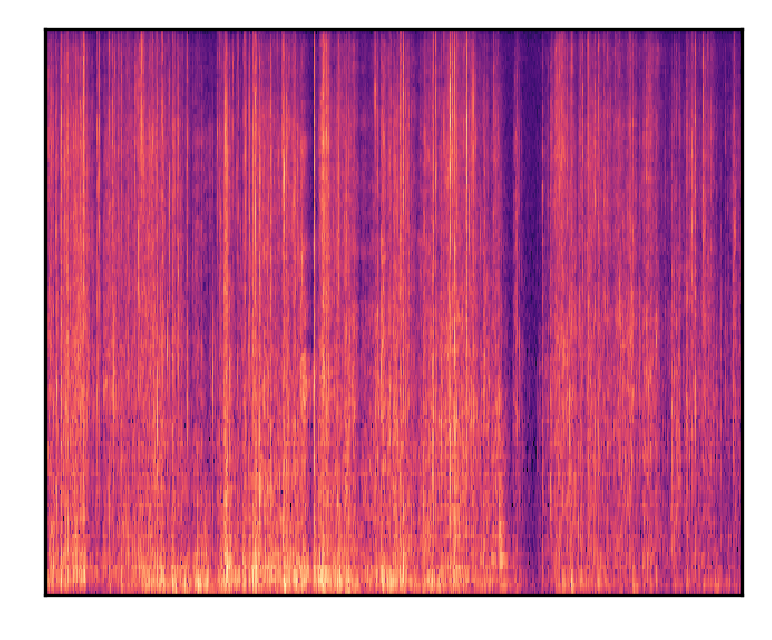 |
| A dog barks and whimpers | |||
| Mel-spectrograms | 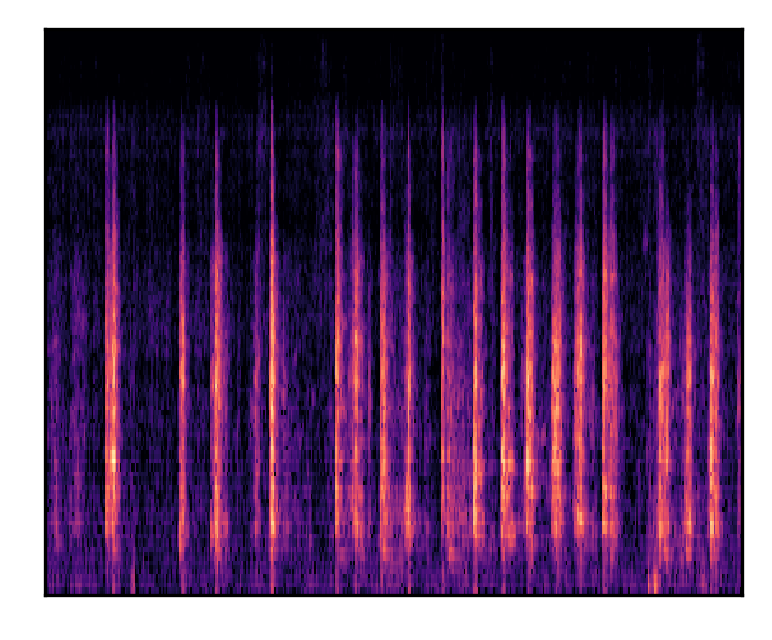 |
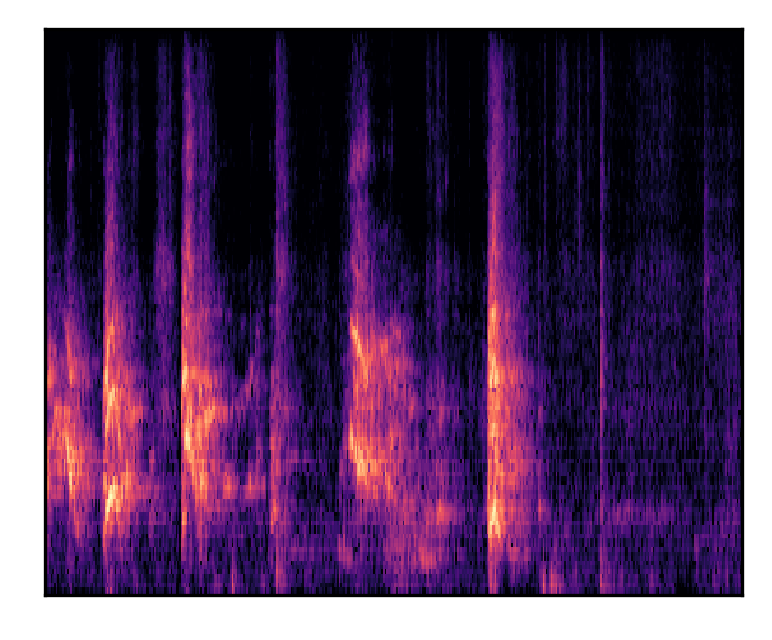 |
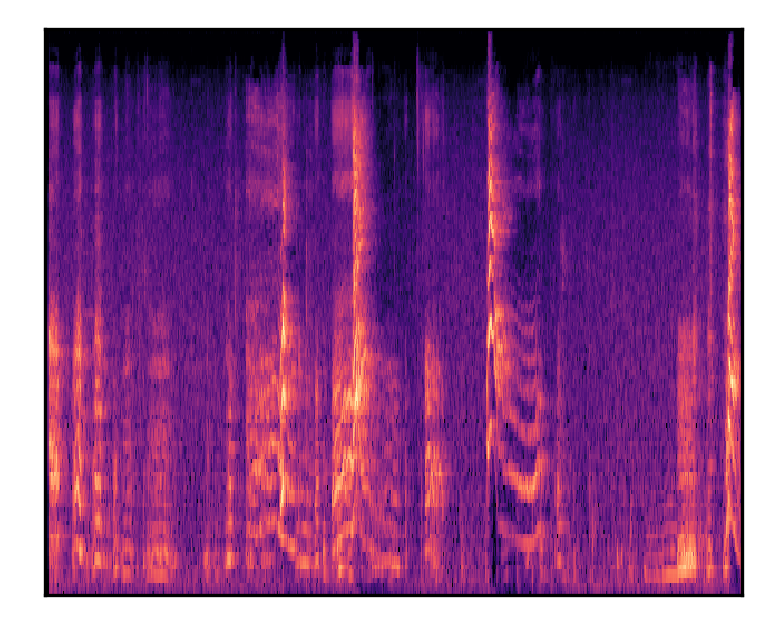 |
| A person is snoring while sleeping | |||
| Mel-spectrograms | 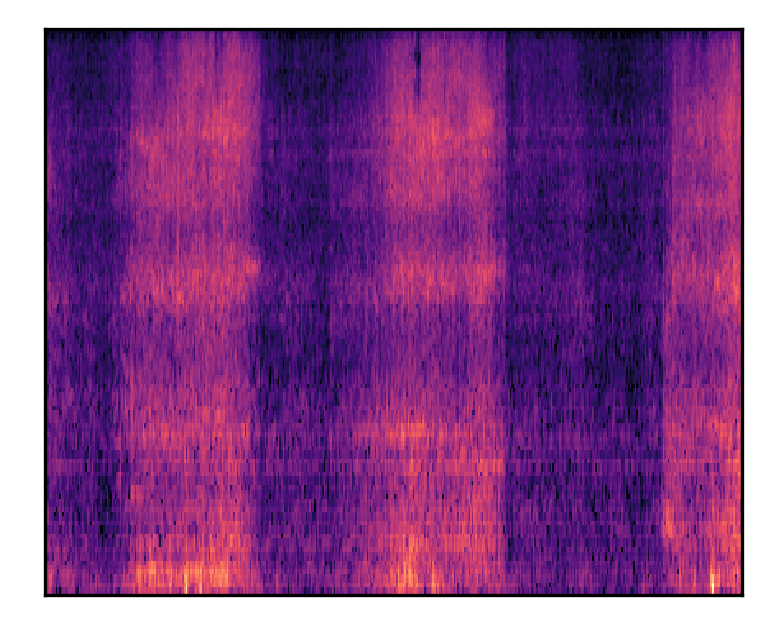 |
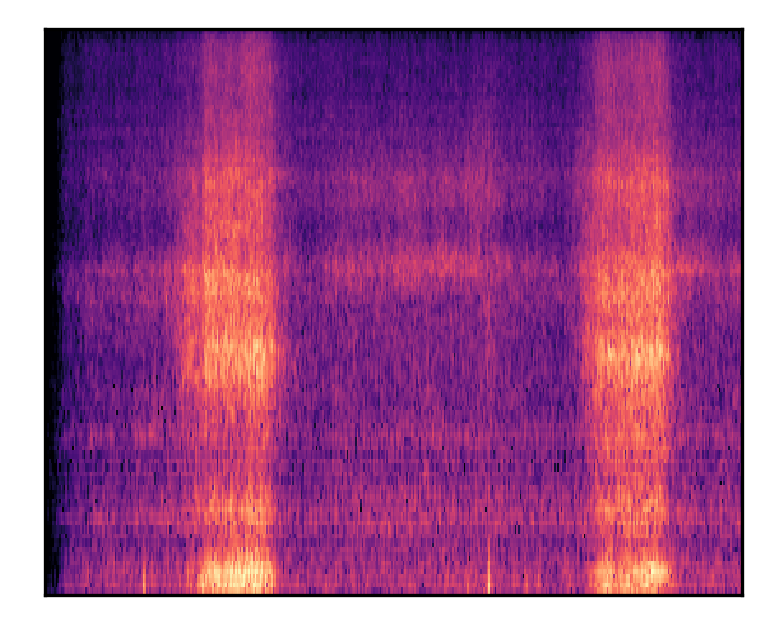 |
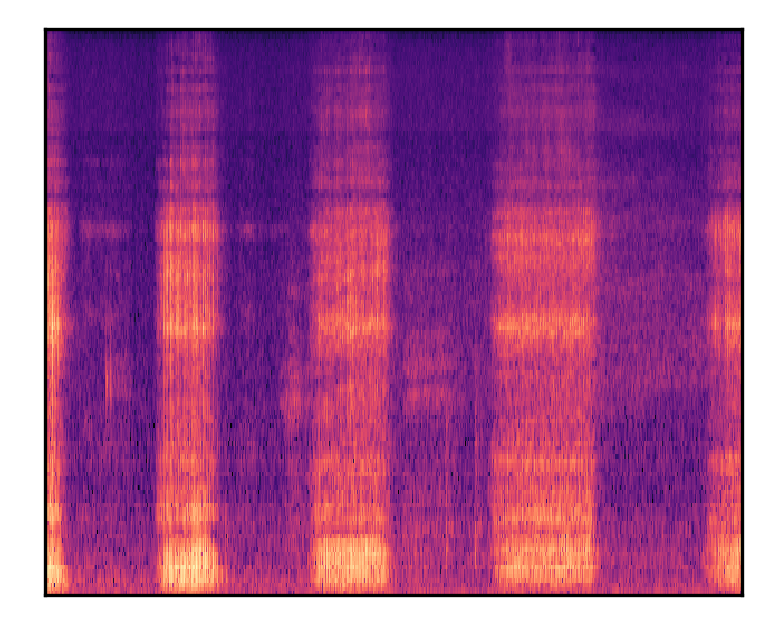 |
Other generated samples by Diffsound model
- Sample 1
- Text input: Someone playing drums
- Generated sound
- Sample 2
- Text input: An engine idles consistently before sputtering some
- Generated sound
- Sample 3
- Text input: A train horn sounds and railroad crossing ring
- Generated sound 1
- Generated sound 2
- Sample 4
- Text input: A clock ticktocks continuously
- Generated sound
- Sample 5
- Text input: Some knocking and rubbing
- Generated sound1
- Generated sound2
- Sample 6
- Text input: Large explosions sound
- Generated sound1
- Generated sound2
- Sample 7
- Text input: An engine runs loudly
- Generated sound
- Sample 8
- Text input: Birds chirp and pigeons vocalize as a vehicle passes by
- Generated sound1
- Generated sound2
- Sample 9
- Text input: A bug is buzzing as it is flying around
- Generated sound
- Sample 10
- Text input: A person is whistling a tune
- Generated sound1
- Generated sound2
- Generated sound3
- Sample 11
- Text input: Thunder roars as rain falls onto a hard surface
- Generated sound1
- Generated sound2
- Sample 12
- Text input: An audience gives applause then a man speaks
- Generated sound
- Sample 13
- Text input: Birds chirp and animals make noise
- Generated sound
- Sample 14
- Text input: A man talks while something sizzles
- Generated sound
- Sample 15
- Text input: Someone is typing on a computer keyboard
- Generated sound1
Links
[Paper] [Bibtex] [Demo GitHub] [TencentAILab] [PKU] [code]